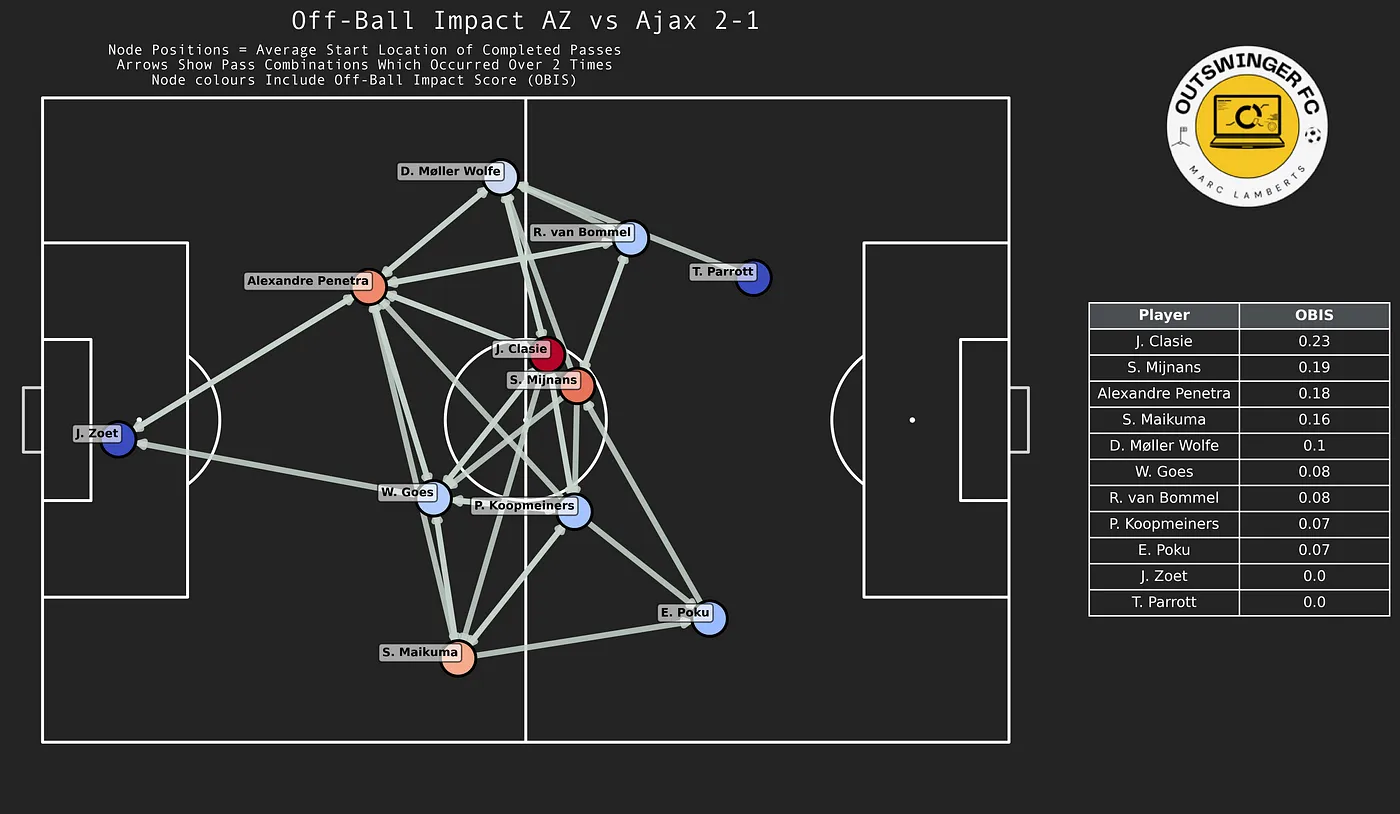
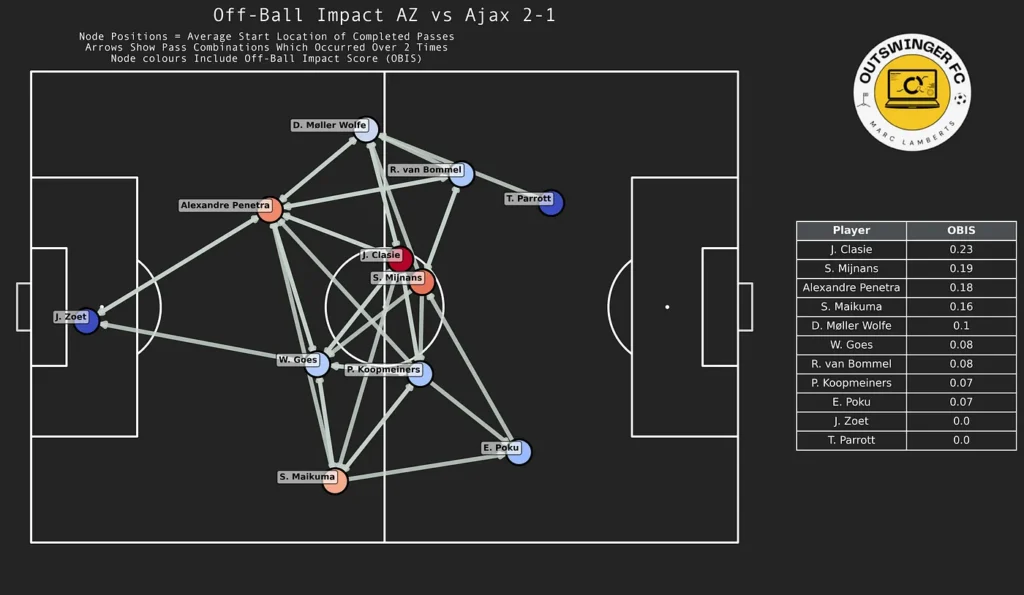
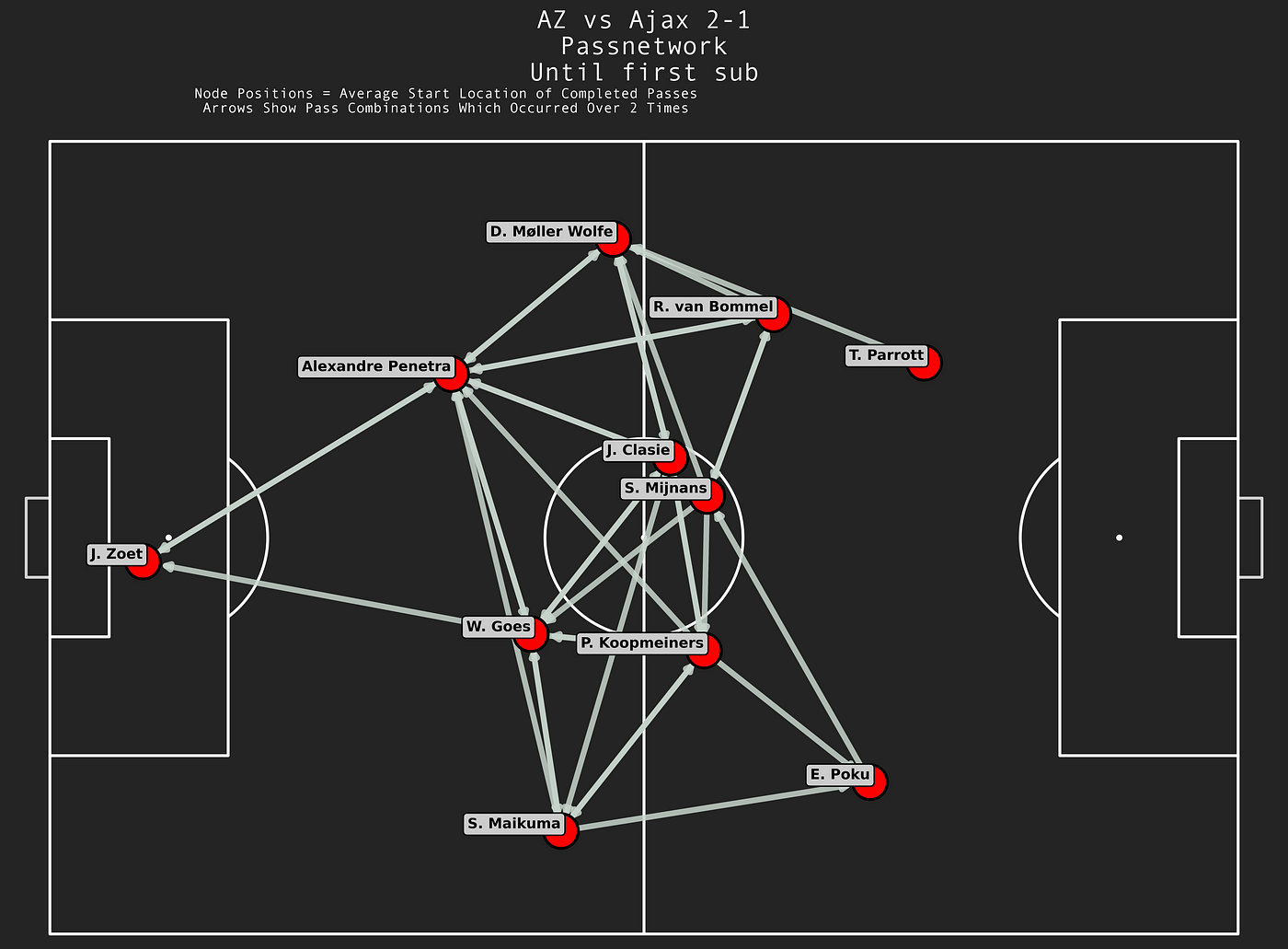
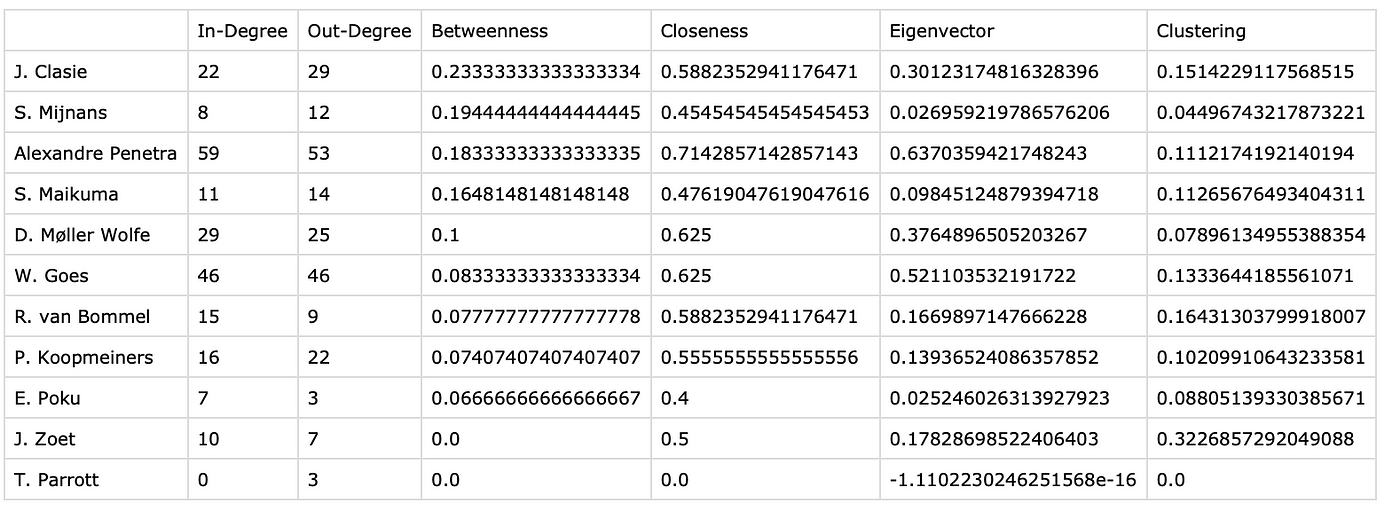
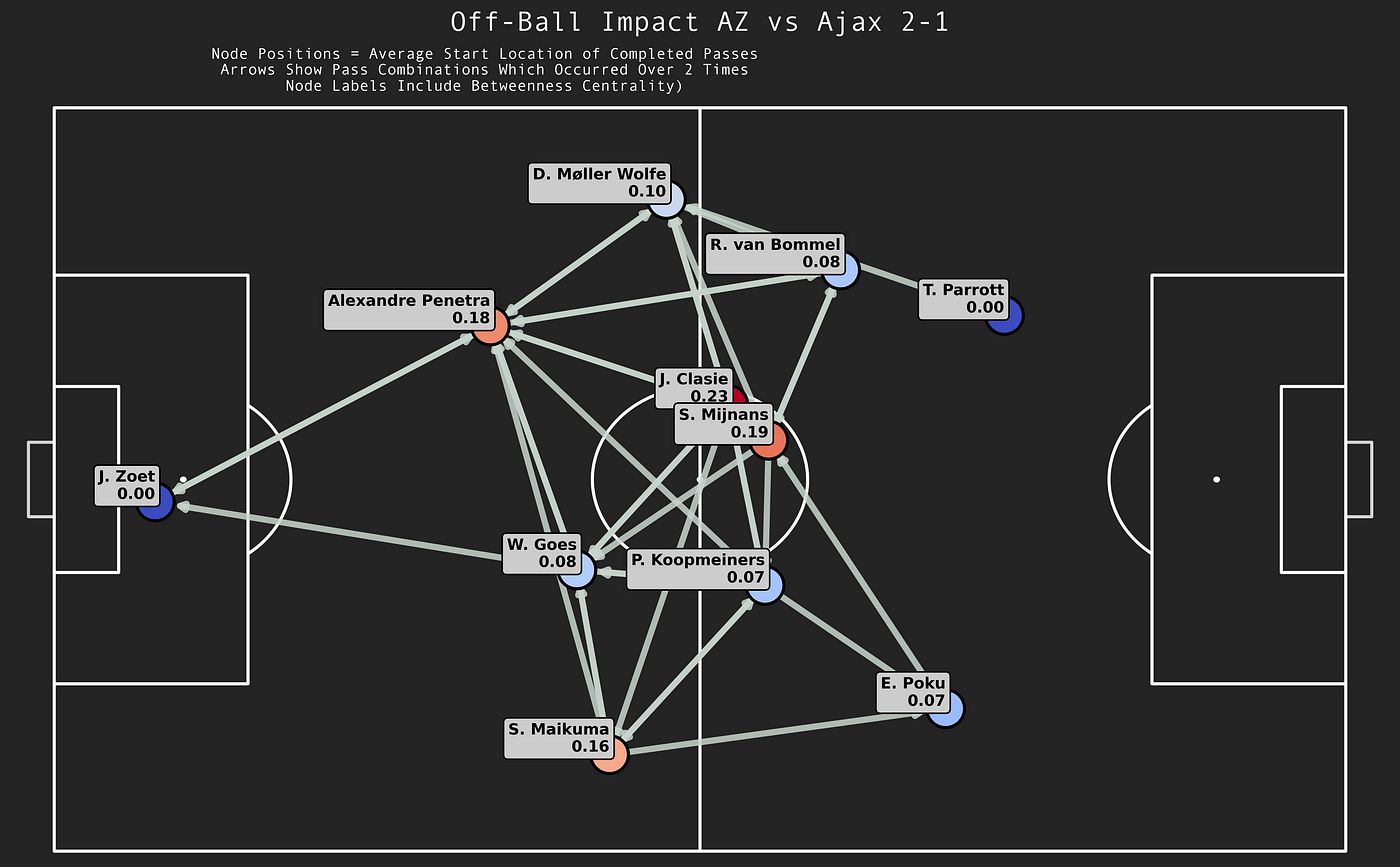
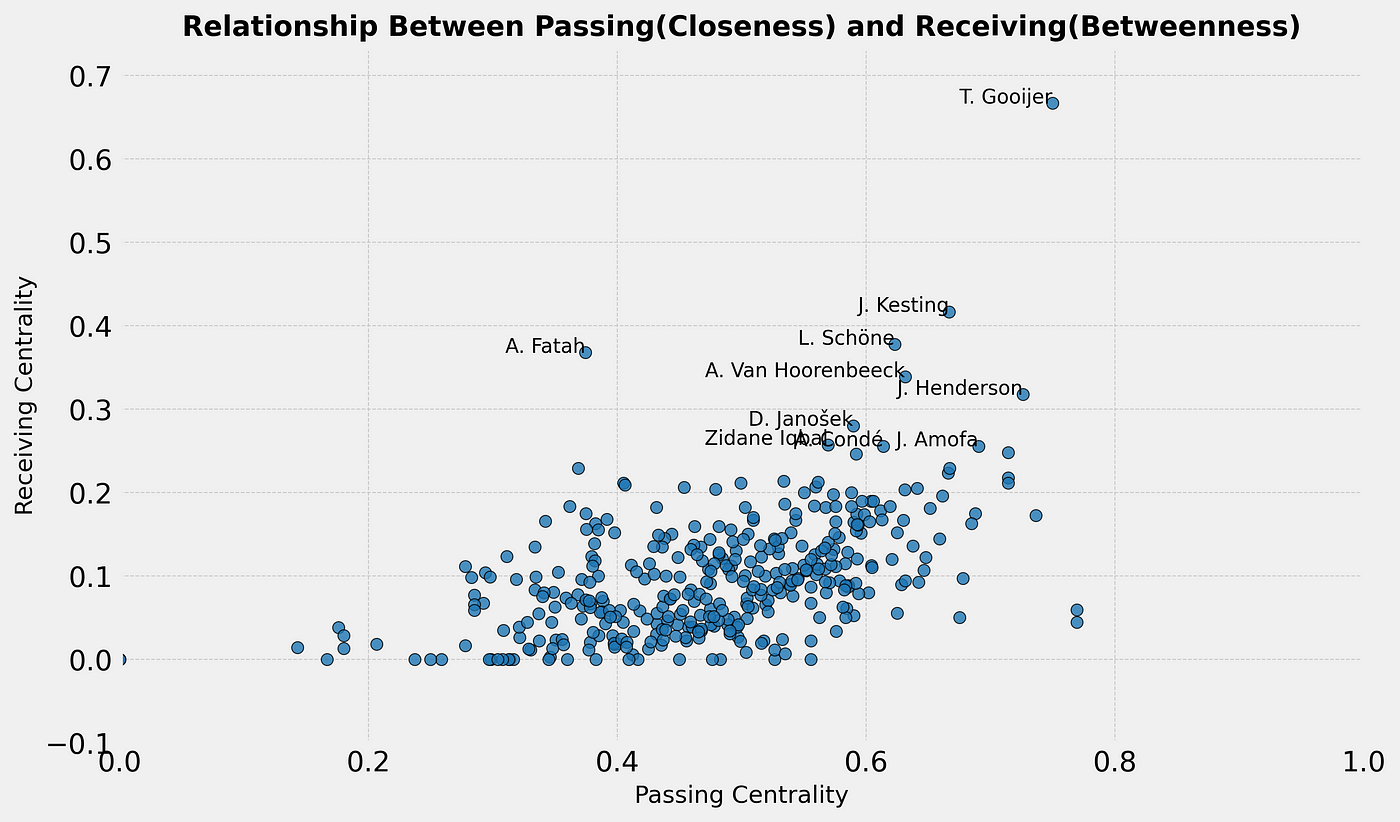
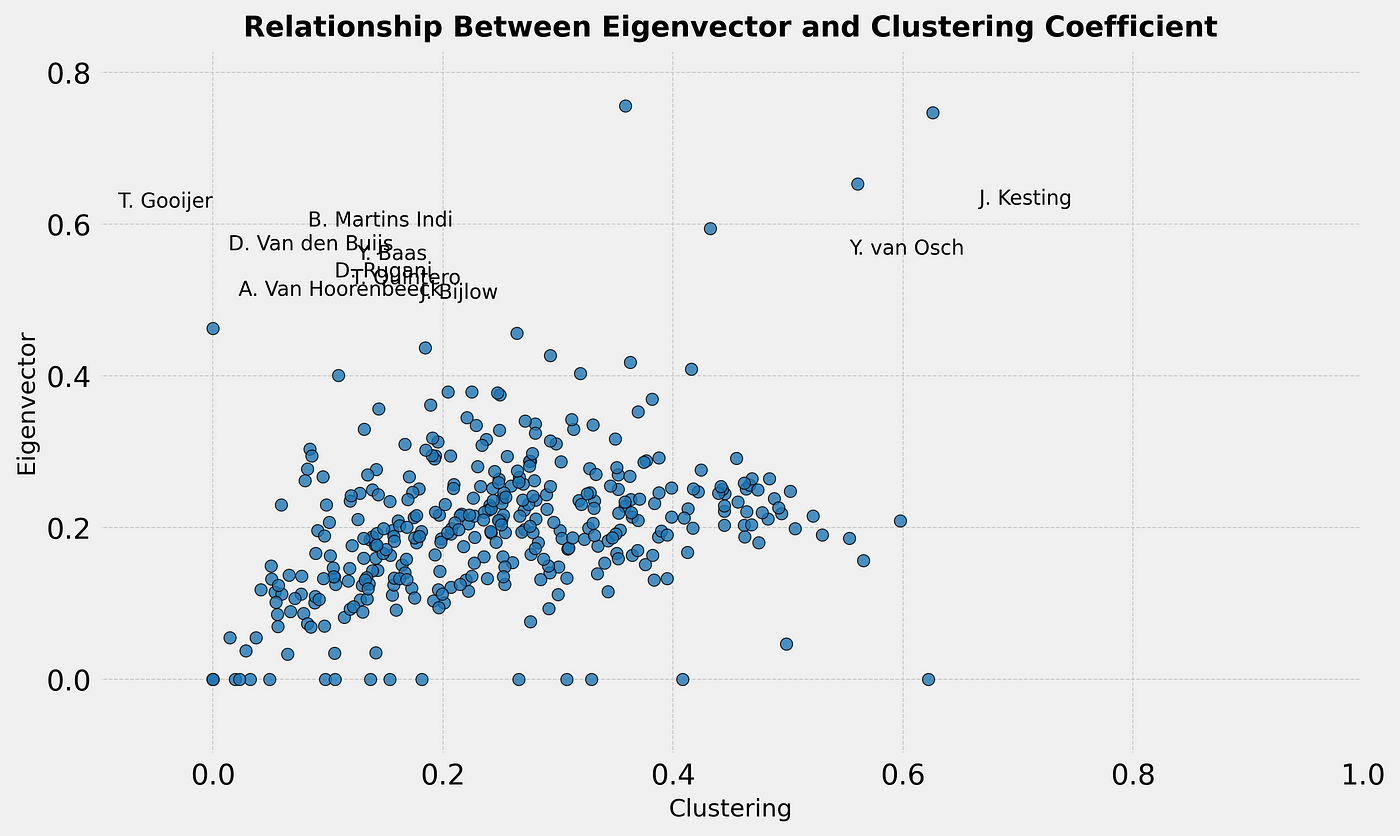
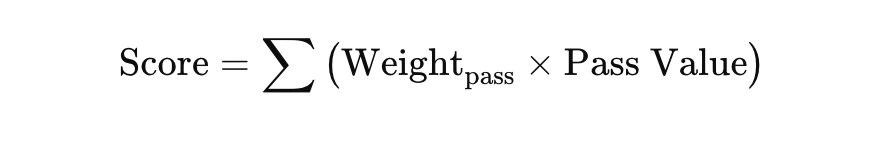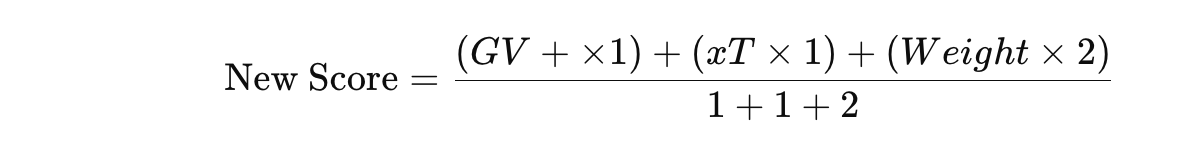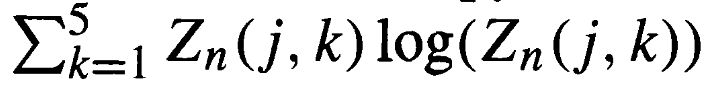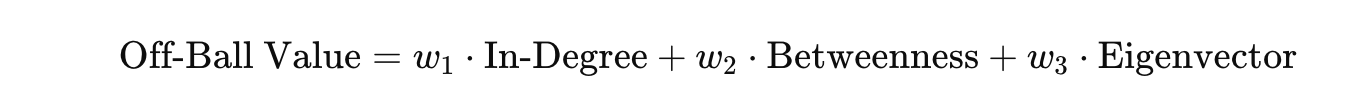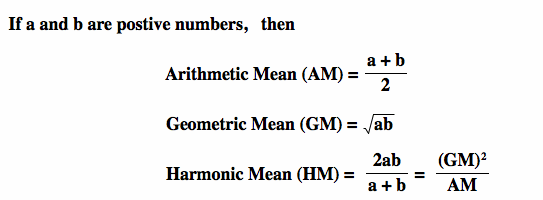It’s finished! That’s my inital thought when I started writing this article and that sentiment comes from weeks of cracking my brain. I have made a shift from using data to do analysis to making some new models myself. It gives me great pleasure to innovate and develop my own models. My aim is to enhance data analysis to jump into the gap that is the lack of defensive football models. So that’s what we are going to do in this article.
Contents
- Why this metric?
- Data collection and representation
- Value models: xPass, xT and EPV
3.1 Expected threat (xT)
3.2 Expected Pass (xPass)
3.3 Expected Possession Value (EPV) - Methodology: xDef
- Analysis: xDEF in French Ligue 1
- Final thoughts
- Sources
1. Why this metric?
I have said this before, but when I look at a lot of the data metrics and data models, I see that they are mostly focused on the attacking side of the game. It focuses on scoring and chance creation most of the time, and if it does not — it focuses on on-ball value. It measures the actions when players have the ball. Whilst I think this is incredibly useful, I feel it gives a very unfair balance in terms of what we focus on in data analysis.
That’s why I want to look closer at a probability model that looks at the defensive side of the game. In other words, I want to measure what defensive actions do to the expected danger of the team in possession. That’s why I have spent weeks on developing a new model called xDef.
xDEF (Expected Defensive Threat Reduction): A metric quantifying the likelihood of a defensive action reducing the opponent’s scoring threat, considering spatial positioning, player actions, and subsequent play outcomes.
In this article we will further explore which data metrics and models are being used, what calculations are needed for it and how we can make it concrete/actionable for day-to-day analysis and scouting.
2.1 Data collection and representation
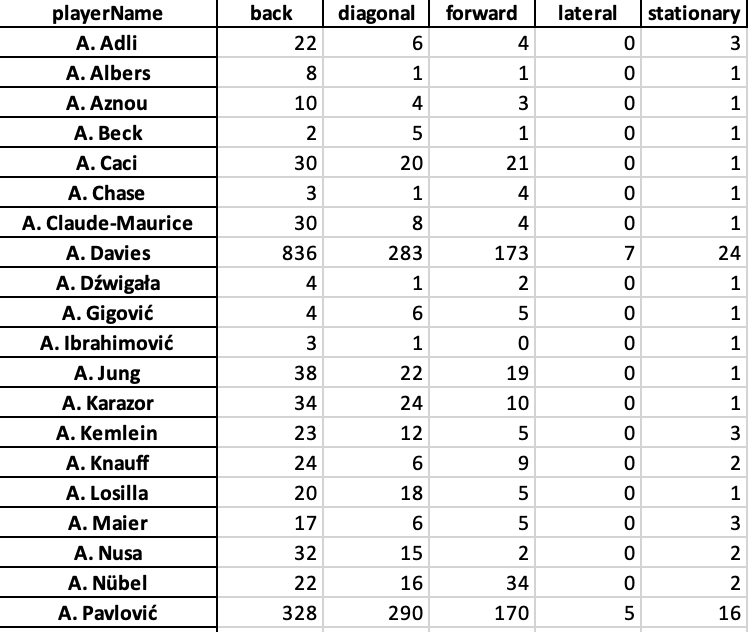
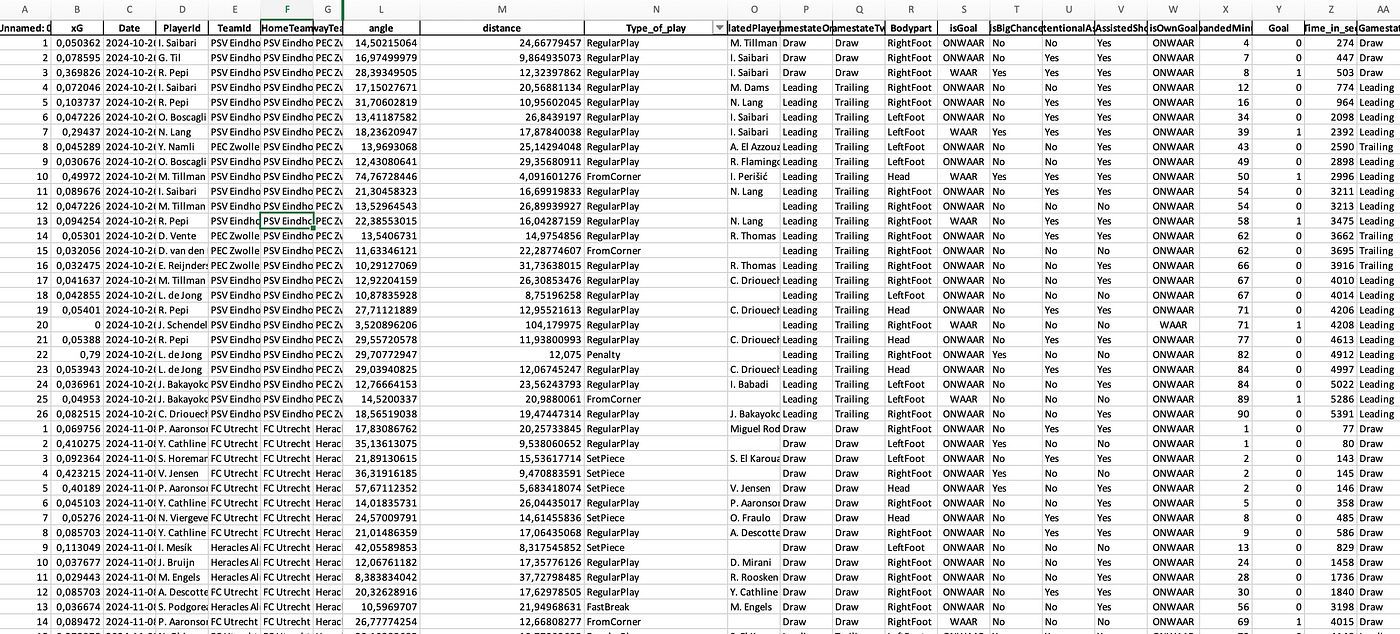
The data used in this article is a combination of already existing metrics, new metrics and newly developed models and scores. This is all done with raw event from Opta and Statsperfom and is combined with physical data from Skillcorner.
The data was last collected on Wednesday 15 January 2025 and consists of the season-level data of the French Ligue 1. For the players’ individual scores and metrics, I have chosen to only select players who have played over 500 minutes in the season so far.
3. Data models
For the creation of the new metric, we will focus on a few data models. To have an understanding what they are, I will explain them briefly and how I will use them in the rest of the research.
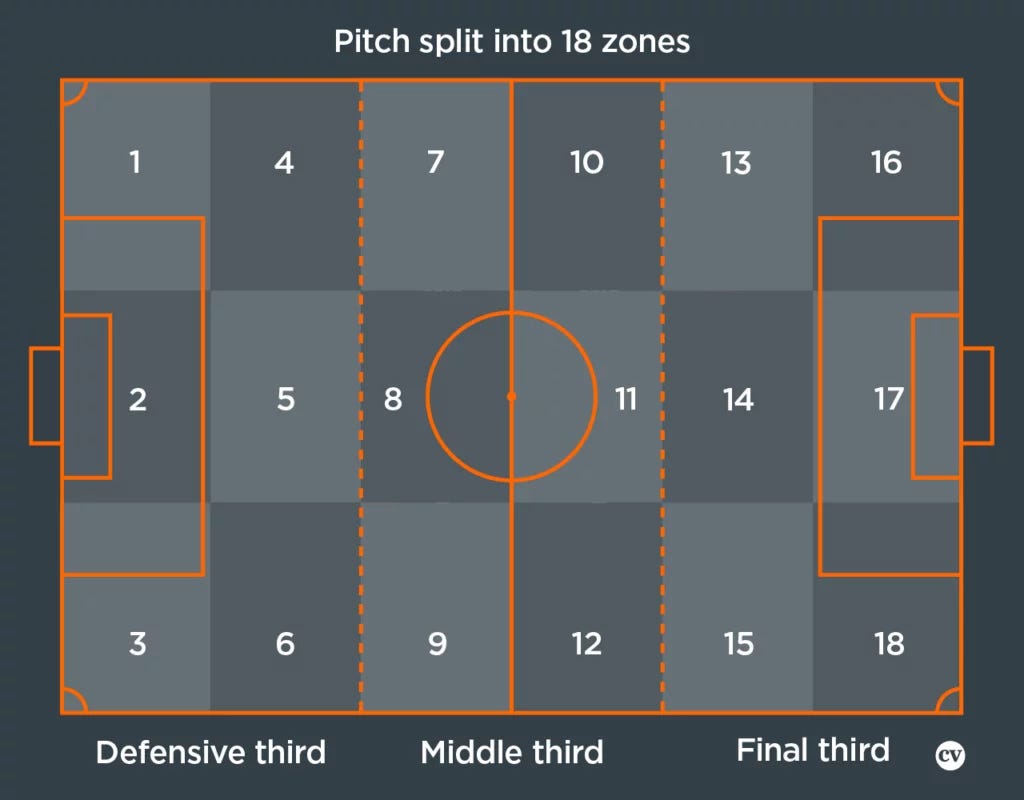
3.1 Expected threat
The basic idea behind xT is to divide the pitch into a grid, with each cell assigned a probability of an action initiated there to result in a goal in the next N actions. This approach allows us to value not only parts of the pitch from which scoring directly is more likely but also those from which an assist is most likely to happen. Actions that move the ball, such as passes and dribbles (also referred to as ball carries), can then be valued based solely on their start and end points, by taking the difference in xT between the start and end cell. Basically, this term tells us which option a player is most likely to choose when in a certain cell, and how valuable those options are. The latter term is the one that allows xT to credit valuable passes that enable further actions such as key passes and shots.

The model was created by Karun Sing in 2018 and you can read about his terminology and explanation here:
Introducing Expected Threat (xT)
Modelling team behaviour in possession to gain a deeper understanding of buildup play.
3.2 Expected Pass (xPass)
Just as expected goals (xG) predicts the likelihood of a shot being scored, our xP framework models the probability of a pass being completed by taking information about the pass and the current possession.
We train a model to predict the likelihood of a pass being completed or not based on its observed outcome (where 0 = incomplete, 1 = complete). In this way, 0.2 xP represents a high-risk pass (i.e. one predicted to be completed only 1 in 5 times) and 0.8 xP represents a relatively low-risk pass (i.e. predicted to be completed 4 in 5 times). — The Analyst
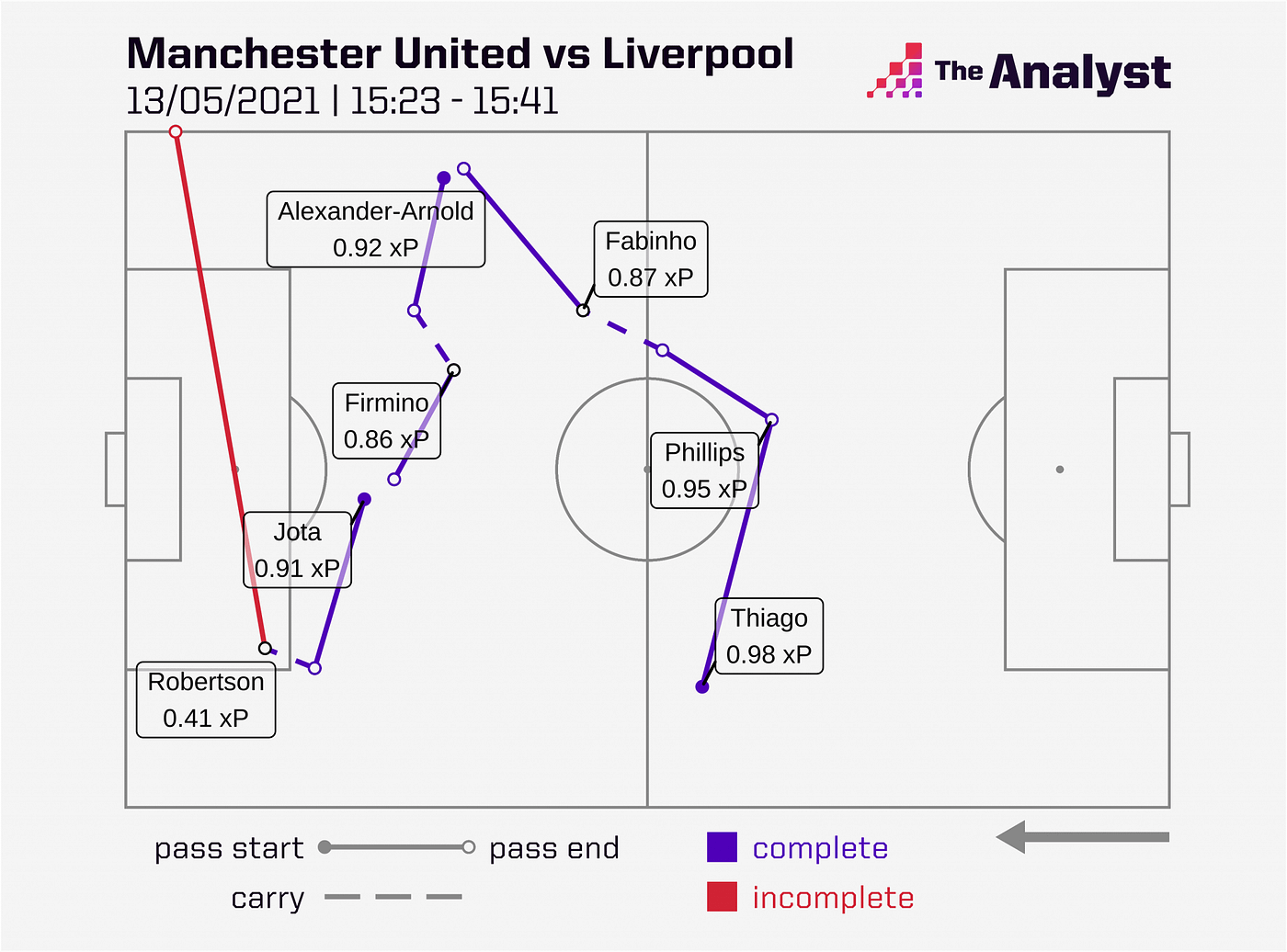
As described by The Analyst above, we can predict the likelihood of a pass being completed. This gives us an idea of how much risk a pass has and how it can contribute to an approach for attack or defence.
3.3 Expected Possession Value (EPV)
Expected Possession Value (EPV) is a sophisticated metric in sports analytics, particularly in soccer, used to quantify the potential value of a team’s possession at any given moment during a match. It estimates the likelihood of a possession resulting in a goal by analyzing various contextual factors such as the ball’s location, player positioning, and game dynamics. EPV draws on large datasets to predict the outcomes of possession sequences, offering a probabilistic view of whether the team is likely to progress the ball effectively, create scoring opportunities, or lose possession.
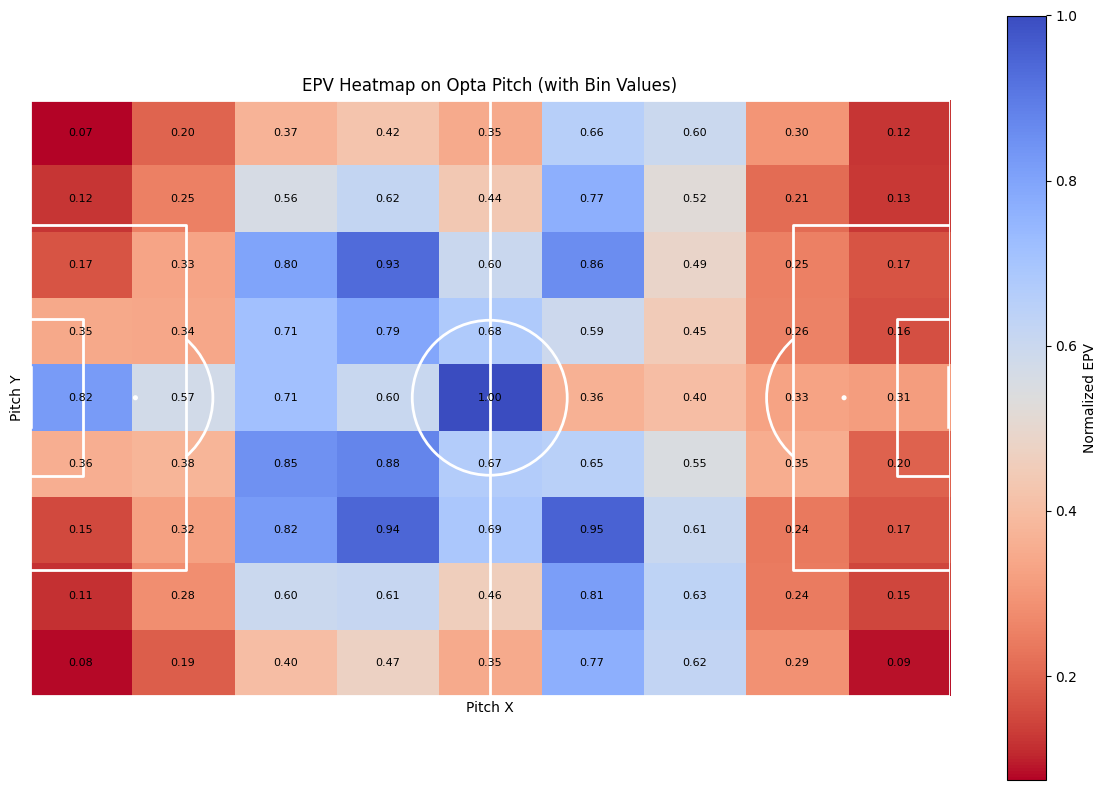
By assigning values to specific actions like passes, dribbles, or tackles, EPV measures contributions beyond traditional statistics such as goals or assists. It gives coaches and analysts deeper insights into team strategies, allowing them to optimise play and assess risks more effectively.
4. Methodology
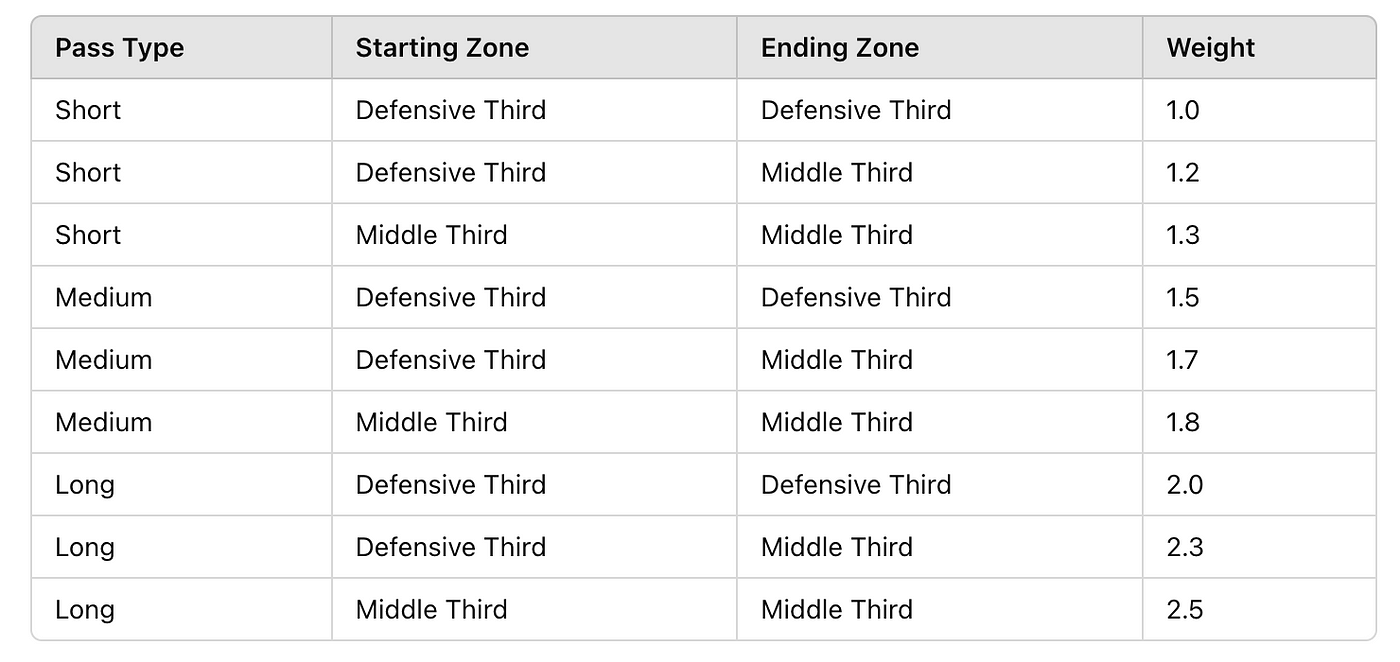
This analysis aims to match passing events with nearby defensive actions within a spatial threshold and evaluate their impact on game dynamics using metrics like expected pass success (xPass), defensive contribution (xDEF), and pre-and post-action danger levels. The analysis incorporates distance weighting to quantify the influence of proximity between events.
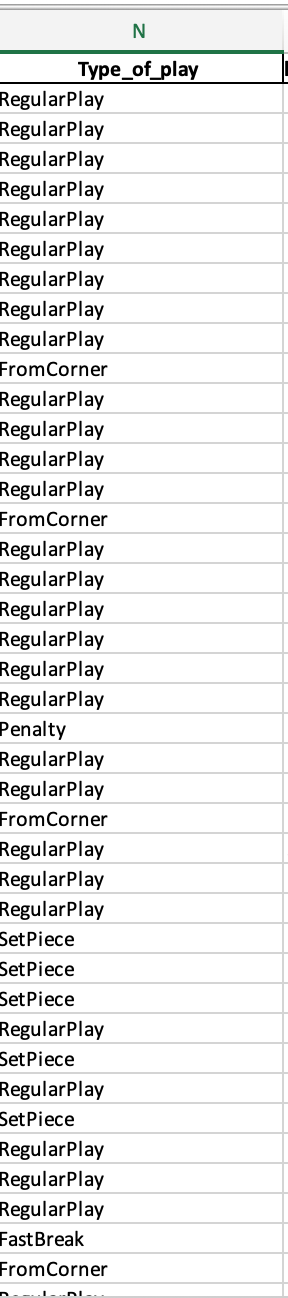
The data we select using Python from our original Excel file are the following metrics:
- playerName
- contestantId
- x, y
- endX, endY
- outcome
- typeId
The dataset contains passing and defensive action events with coordinates (x,y) player identifiers, and outcomes. Passes are filtered using typeId == 1. Only successful passes (outcome=1) are further analyzed. Receivers are identified by matching subsequent events (endX, endY) from a different player and team.
Following that I want to match defensive actions or pressures if they fall within a 10 mether threshold of the opposition. The spatial proximity is noted; For each pass, defensive actions from a different team are identified if they fall within a threshold distance of 10 meters.
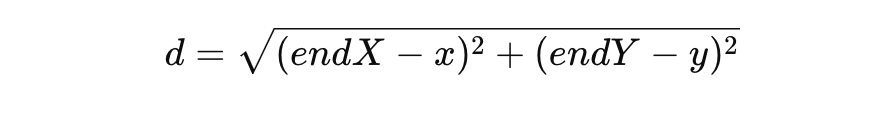
After we get the data and new metrics, we go on to the next step. We are going to calculate two different metrics: pre-danger and post-danger based on EPV. The PreDanger metric incorporates the EPV of the initial pass location and adjusts it based on the distance and angle to the pass endpoint.
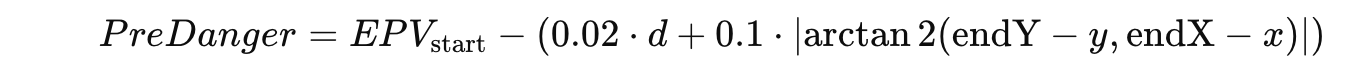
- EPVstart is the EPV value at the starting location of the pass.
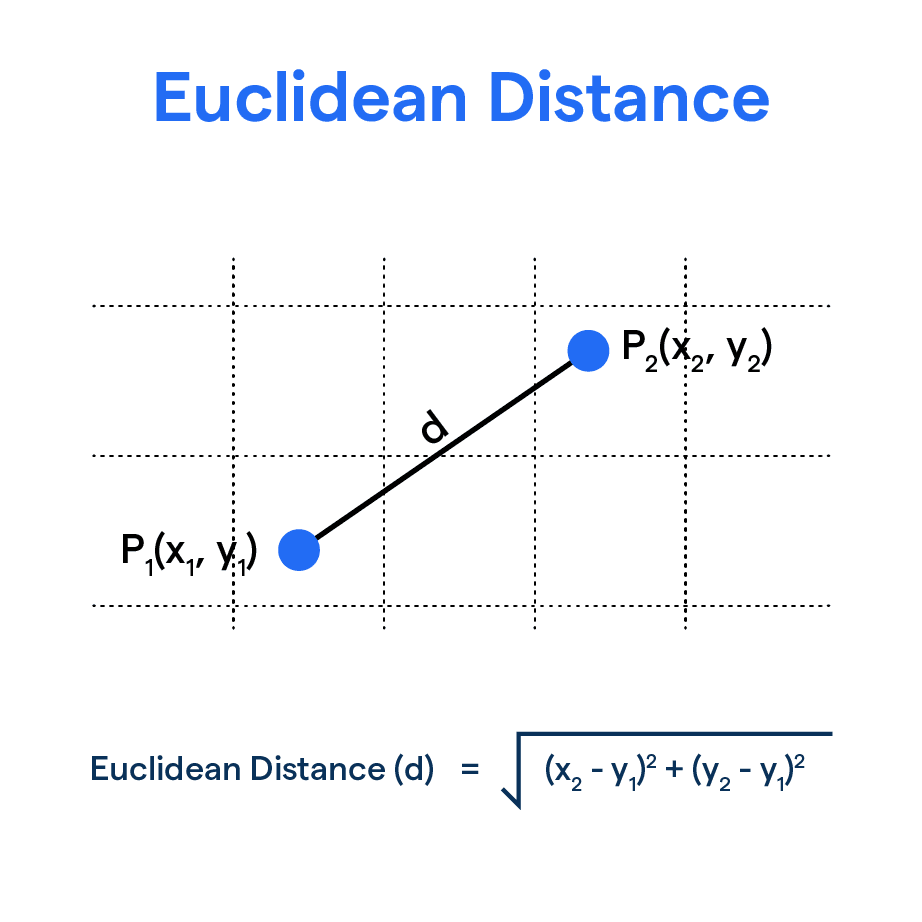
- d is the distance between the starting and ending positions of the pass.
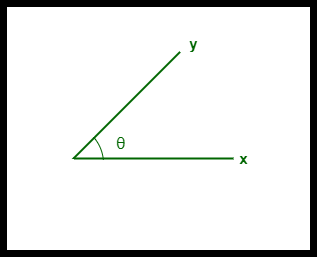
- arctan2 accounts for the directional change, reflecting how difficult the pass is regarding angle.
Post-action danger is adjusted based on the defensive outcome and the EPV of the pass endpoint. Defensive success reduces the PostDanger by half, while unsuccessful actions leave it unchanged.
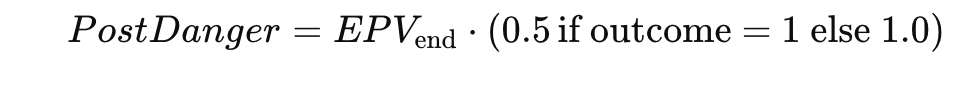
Where:
- EPVend is the EPV value at the ending location of the pass.
- Defensive outcome (outcome=1) indicates a successful defensive intervention, halving the danger.
The next and final step is xDef. It can be quantified using the expected reduction in danger before and after the action, adjusted for spatial proximity. It considers pre-action danger (PreDanger), post-action danger (PostDanger, and a distance-based weight (DistanceWeight) to account for the defender’s proximity to the play.

- PreDanger⋅xPass combines the danger level with the likelihood of the pass succeeding, offering a more nuanced starting value for defensive impact.
- PostDanger reflects the defender’s influence, reduced further in cases of successful defensive actions.
- DistanceWeight adjusts the overall impact based on the spatial proximity of the defensive action.
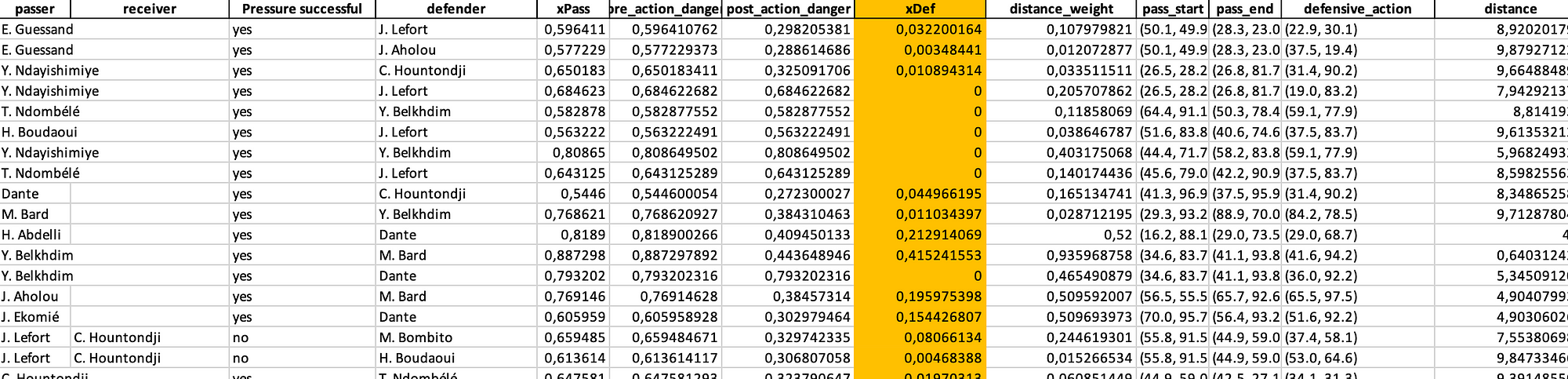
In the end we calculate all the new metrics and save them to an excel file. From that excel file we can start working on the analysis, that gives us a better idea of what xDef means for teams and players in Ligue 1.
5. Analysis: Ligue 1
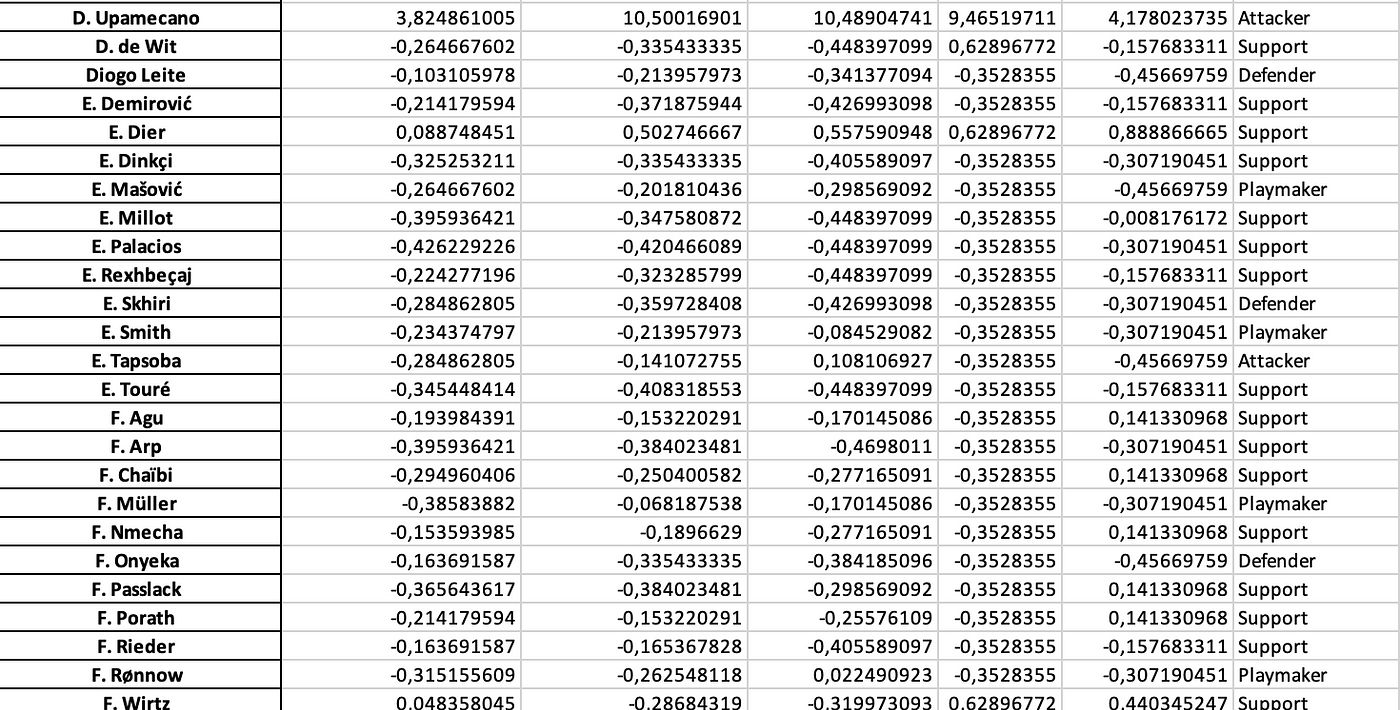
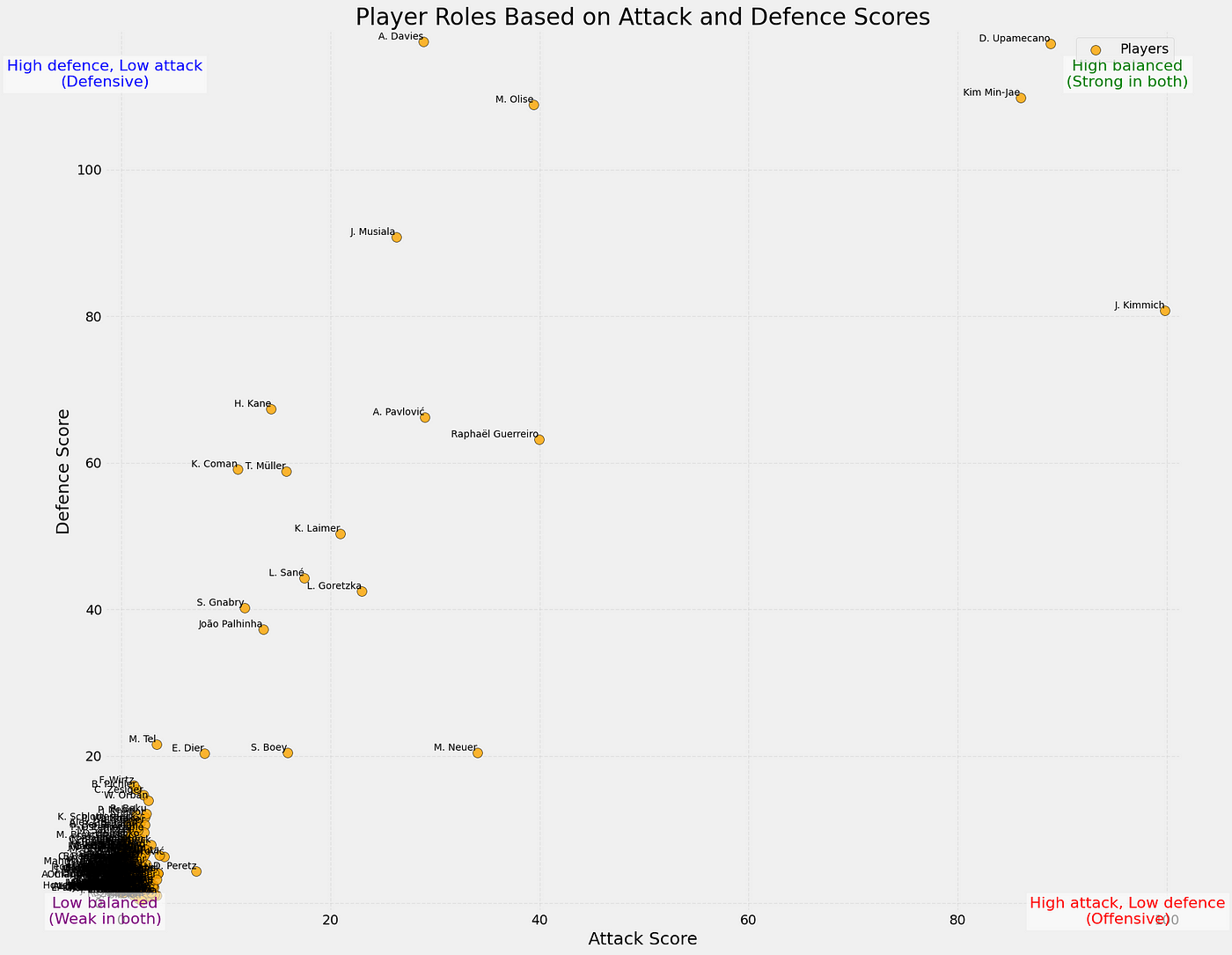
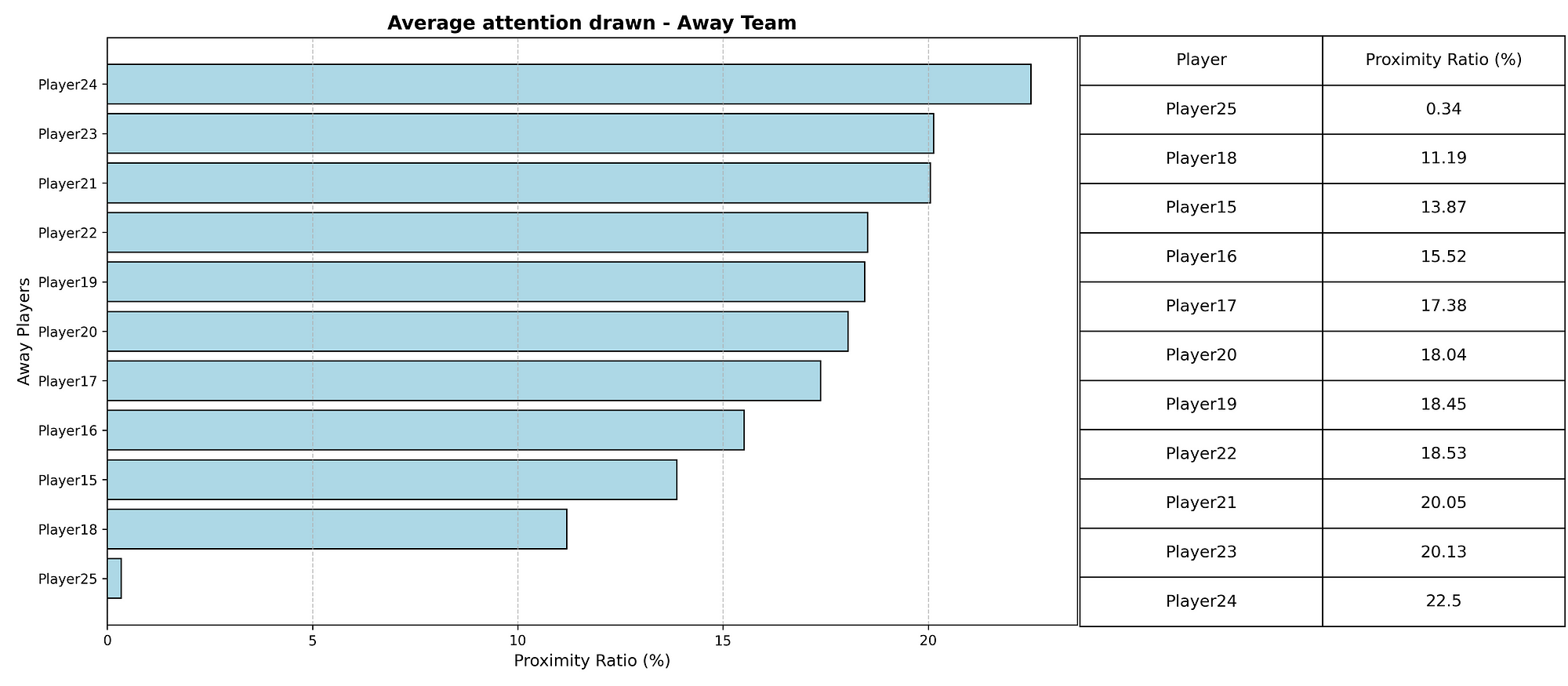
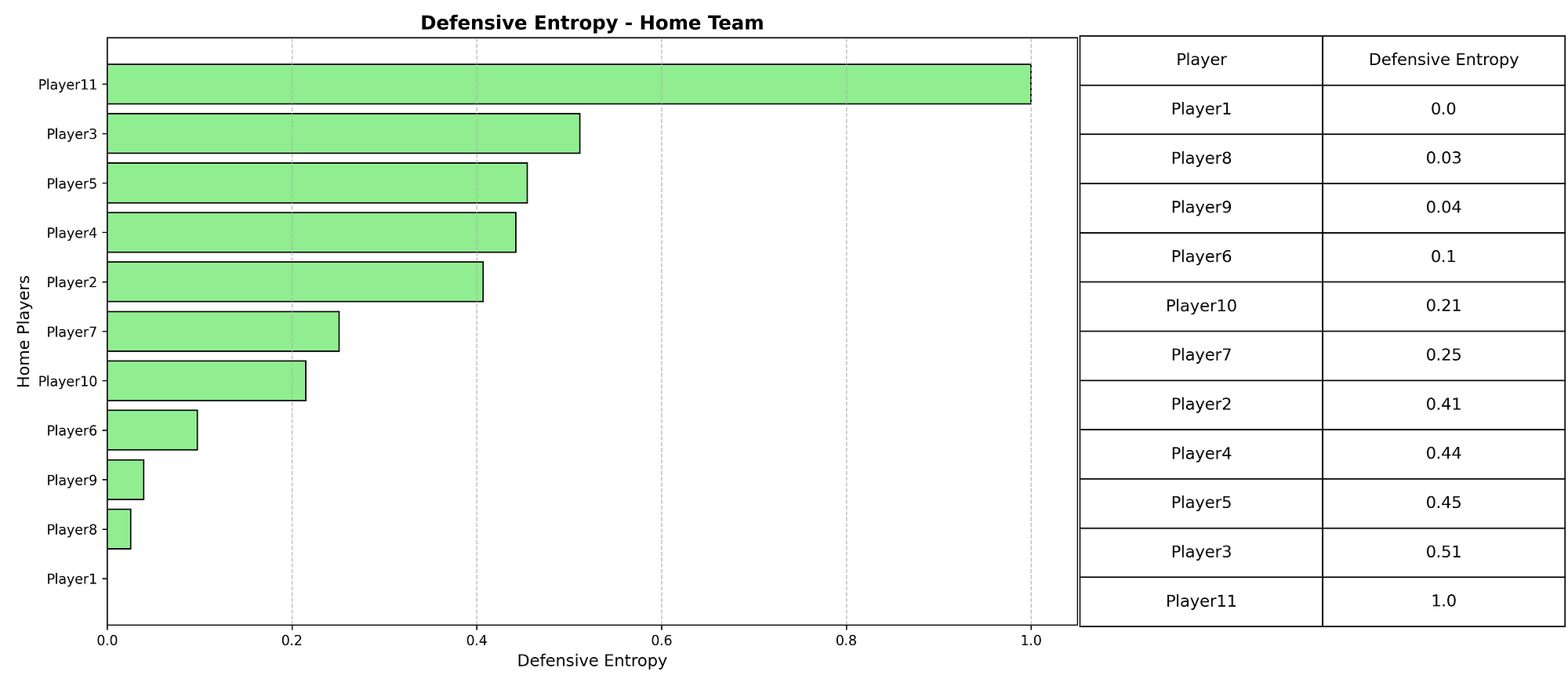
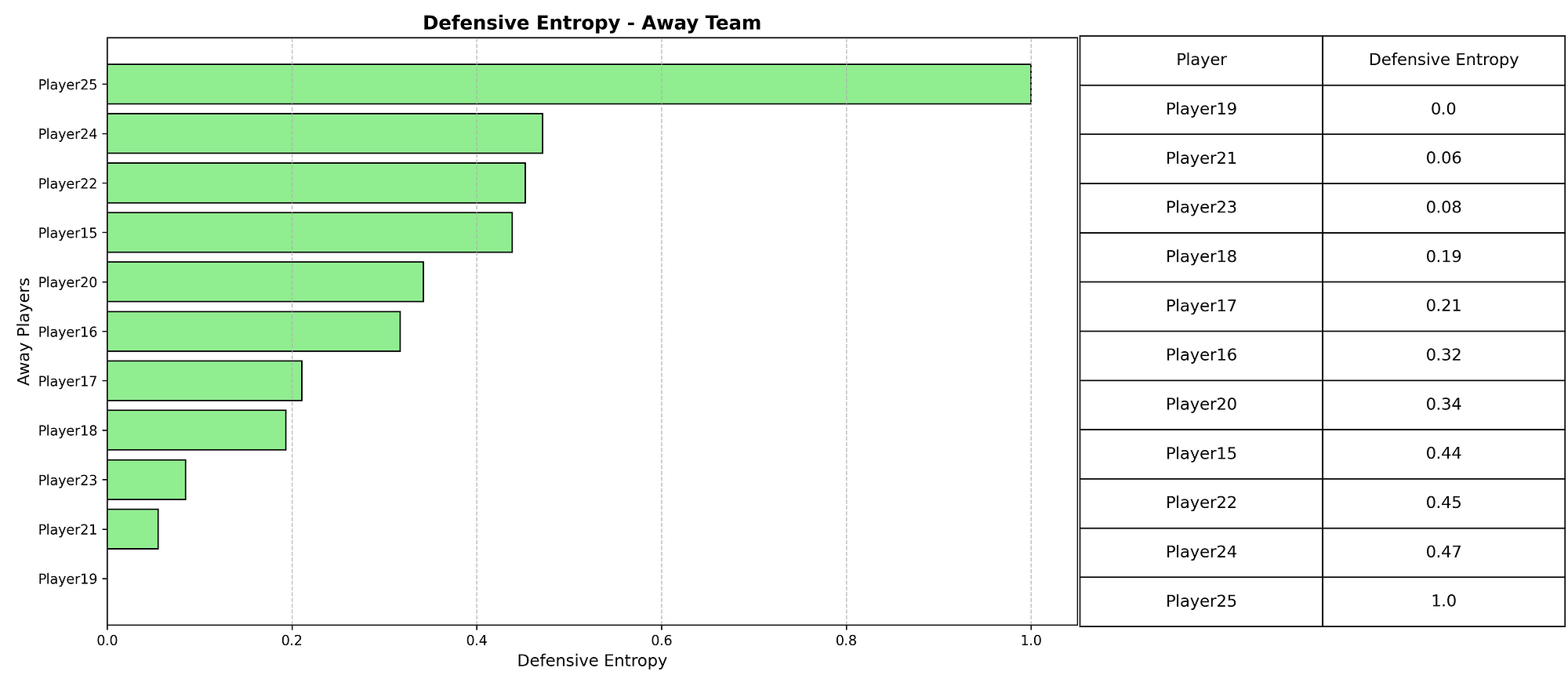
So, now we want to look at which players perform the best in terms of xDef. In the scatterplot below you can see the relation between xPass and xDef.
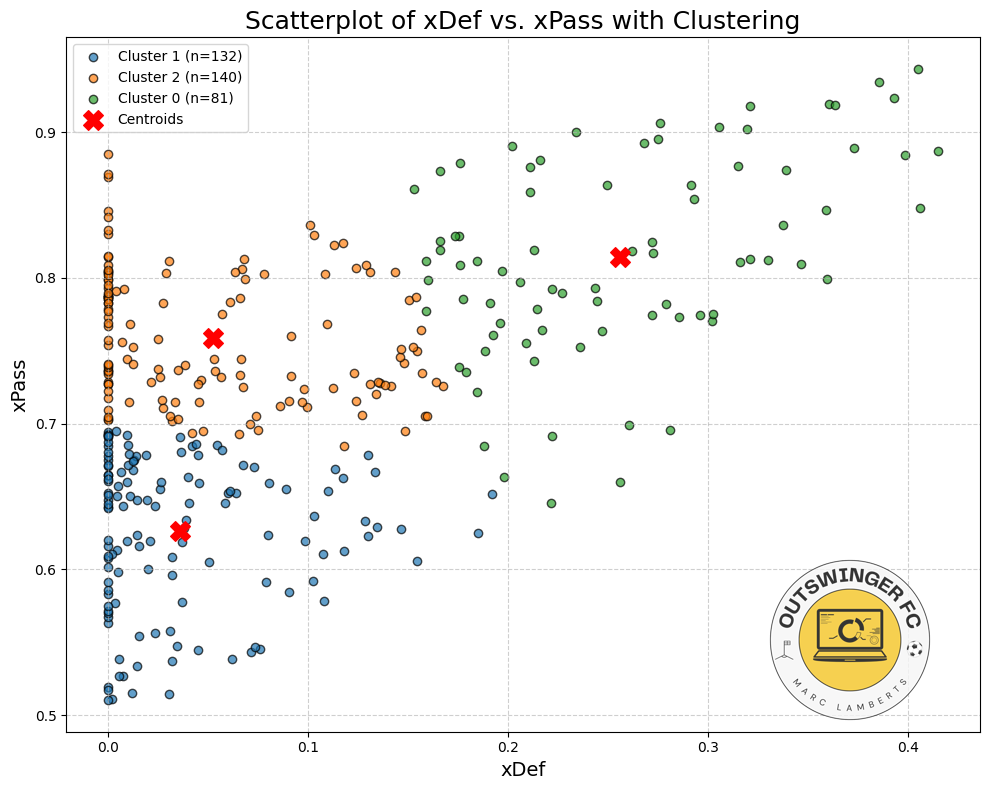
In the scatterplot above we have attempted to cluster the data and give it a meaningful insight. Most are in cluster 2, which have relatively high xPass values, but under average xDef. Meaning it is more difficult to affect the threat. After that follows cluster 1, which has under average xPass, but also under average xDef, so these don’t have great threat but also arent’ affected as much. The last cluster is cluster 0, which do have relatively average to high xPass, and also have higher xDef, signifying their defensive activity intensity and affection.
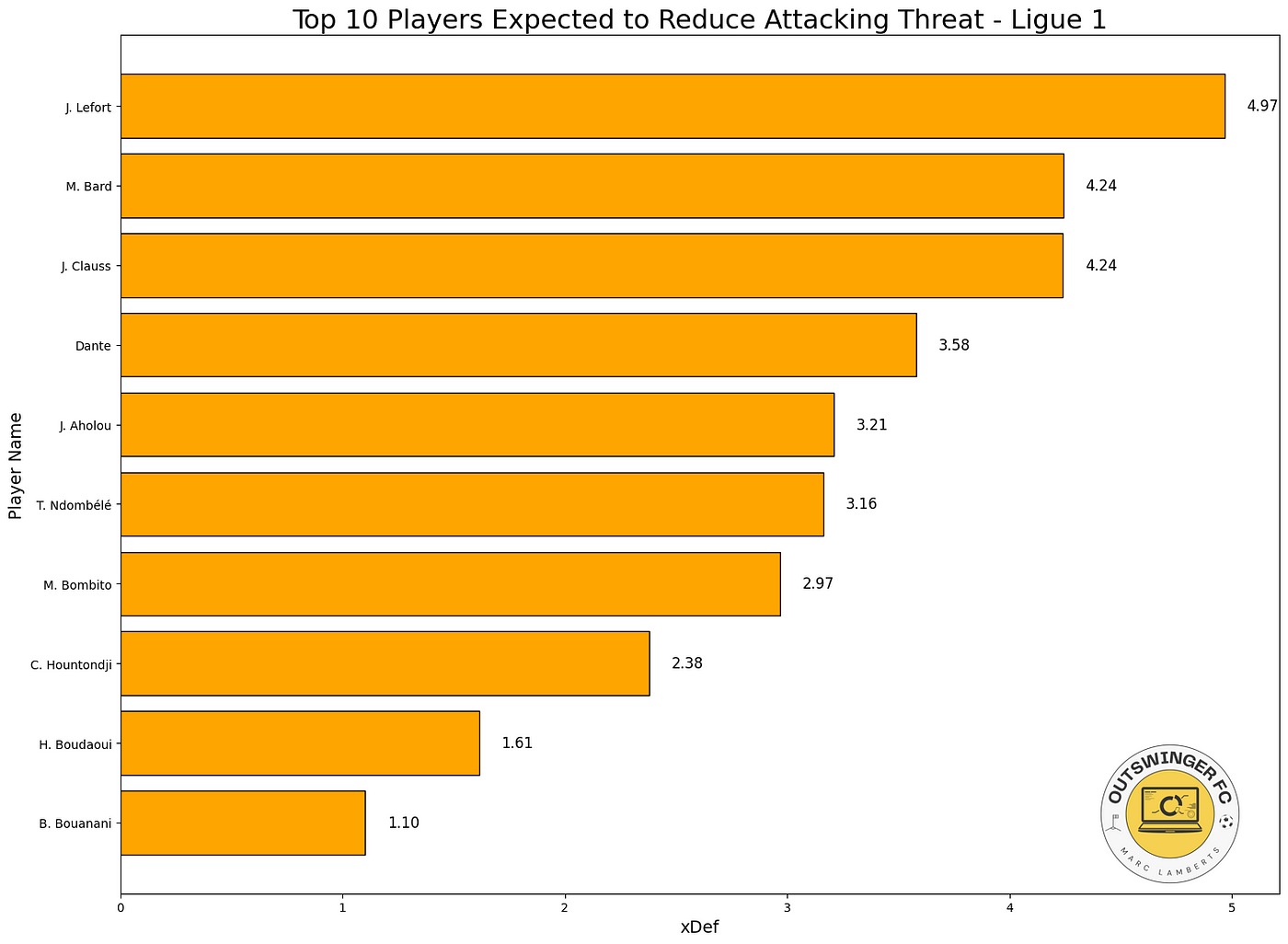
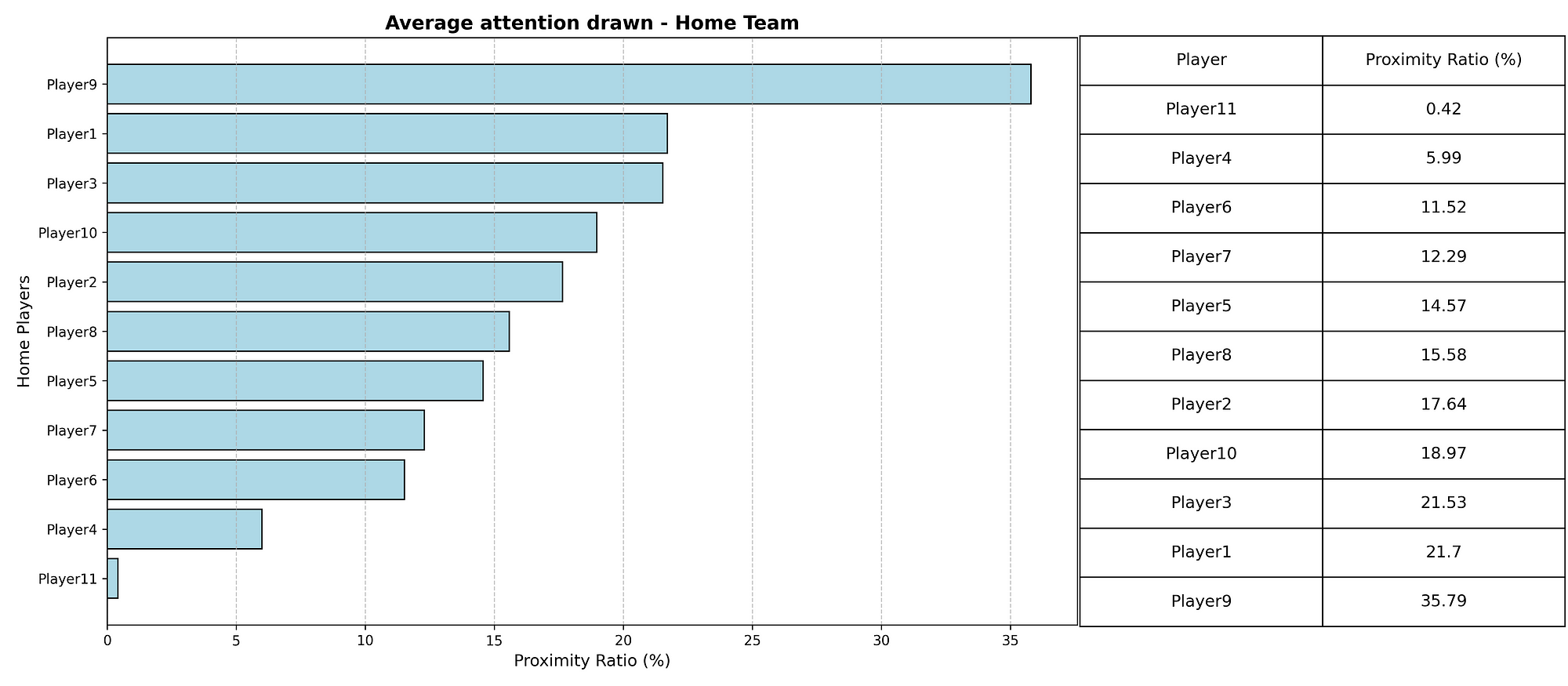
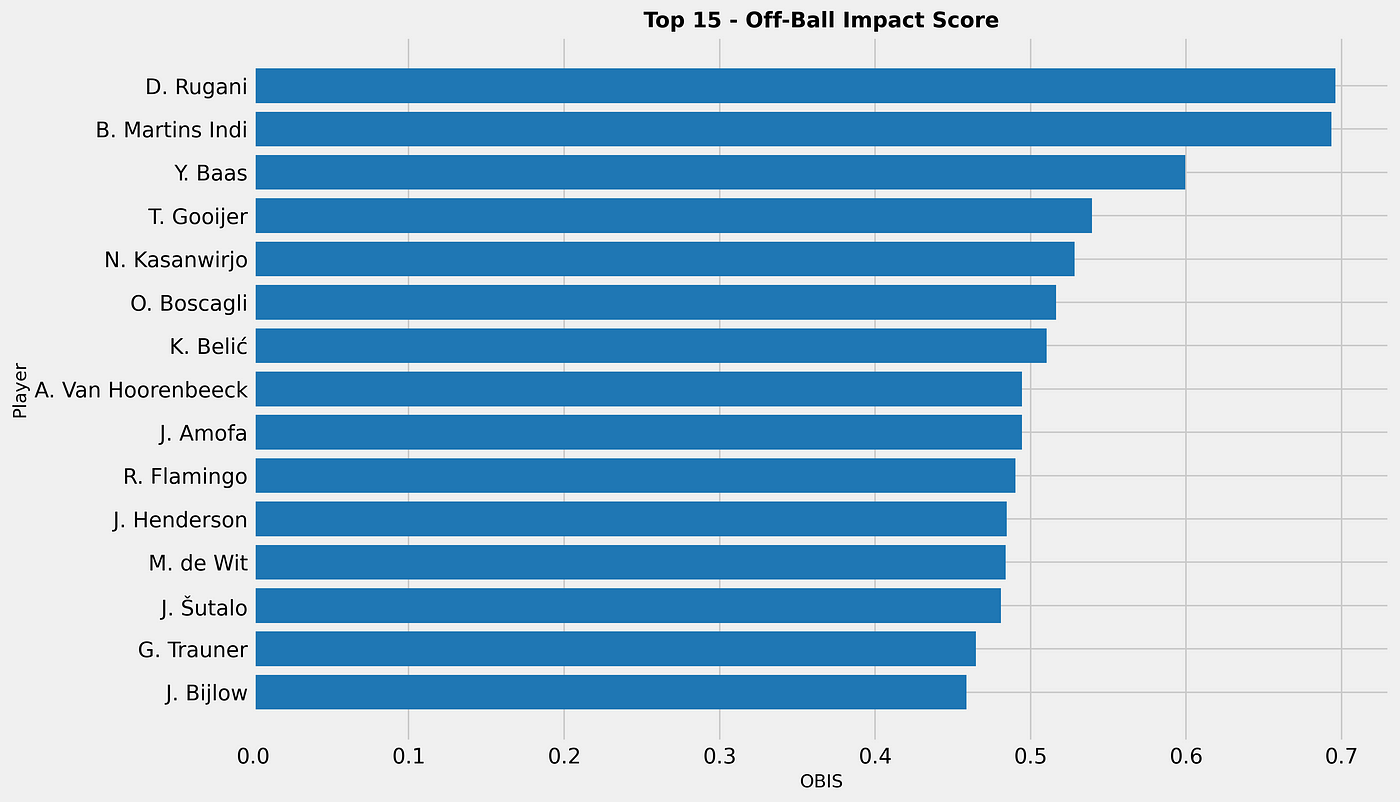
When we look at the total xDef in the season so far, these players do perform the best. The number quantifies how much a defender reduces the attacking threat of their opponents. A value of 4,97 like J. Lefort has, means that across the analysed period, the player reduced the likelihood of goals by a total of 4 (on a probability scale).
6. Final thoughts
The idea of this research was to create a model that gives values to off-the-ball defensive activities and gives probability of reducing threat. This is based on distance/pressures and defensive activity on the ball, but still lacks the spatial data from the tracking data. This will be done for a 2.0 version.
However, this metric/model gives us insight how a defensive players makes an impact in reducing attacking threat by moving into the passes of the attacking team.
7. Sources
Expected Threat (xT):
Singh, K. (2018). Introducing Expected Threat (xT). Retrieved from https://karun.in/blog/expected-threat.html
StatsBomb. (n.d.). Possession Value Models Explained. Retrieved from https://statsbomb.com/soccer-metrics/possession-value-models-explained/
Soccerment. (n.d.). Expected Threat (xT). Retrieved from https://soccerment.com/expected-threat/
Expected Possession Value (EPV):
Fernández, J., Bornn, L., & Cervone, D. (2020). A Framework for the Fine-Grained Evaluation of the Instantaneous Expected Value of Soccer Possessions. Retrieved from https://arxiv.org/abs/2011.09426
Fernández, J., Bornn, L., & Cervone, D. (2019). Decomposing the Immeasurable Sport: A Deep Learning Expected Possession Value Framework for Soccer. Retrieved from https://www.lukebornn.com/papers/fernandez_sloan_2019.pdf
xPass:
Decroos, T., Van Haaren, J., & Davis, J. (2019). Valuing On-the-Ball Actions in Soccer: A Critical Comparison of xT and VAEP. Retrieved from https://tomdecroos.github.io/reports/xt_vs_vaep.pdf
Decroos, T., Van Haaren, J., & Davis, J. (2019). Valuing On-the-Ball Actions in Soccer: A Critical Comparison of xT and VAEP. Retrieved from https://dtai.cs.kuleuven.be/sports/blog/valuing-on-the-ball-actions-in-soccer-a-critical-comparison-of-xt-and-vaep/
Defensive Actions:
Merhej, C., Beal, R., Ramchurn, S., & Matthews, T. (2021). What Happened Next? Using Deep Learning to Value Defensive Actions in Football Event-Data. Retrieved from https://arxiv.org/abs/2106.01786
StatsBomb. (n.d.). Defensive Metrics: Measuring the Intensity of a High Press. Retrieved from https://statsbomb.com/articles/soccer/defensive-metrics-measuring-the-intensity-of-a-high-press/
Expected Goals (xG) Models:
Wikipedia contributors. (2023, September 15). Expected Goals. In Wikipedia, The Free Encyclopedia. Retrieved from https://en.wikipedia.org/wiki/Expected_goals
Pollard, R., & Reep, C. (n.d.). Introducing Expected Goals: A Tutorial. Retrieved from https://soccermatics.readthedocs.io/en/latest/lesson2/introducingExpectedGoals.html