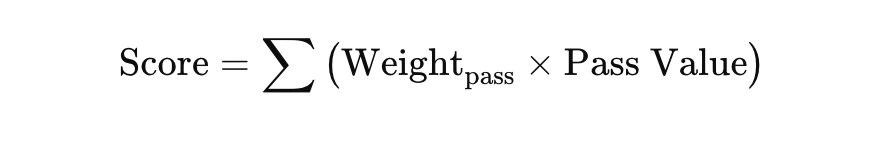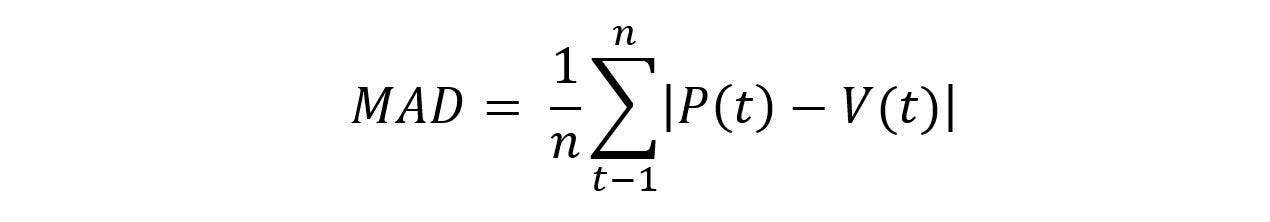In data departments all over elite sports and in football in particular, we create and develop metrics. To make them actionable, we categorise them into the vital parts of data called KPI. KPI are Key Performance Indicators that indicate the relevant data metrics for a specific player or team. They always look at performance, but in this article I want to look more closely at intention.
Intention is often a good way to reflect on coaching and training session. Iy assesses playing style even when the performance isn’t the best exactly. By looking at intentions we can give much more insight into players’ individual preferences in a larger collective.
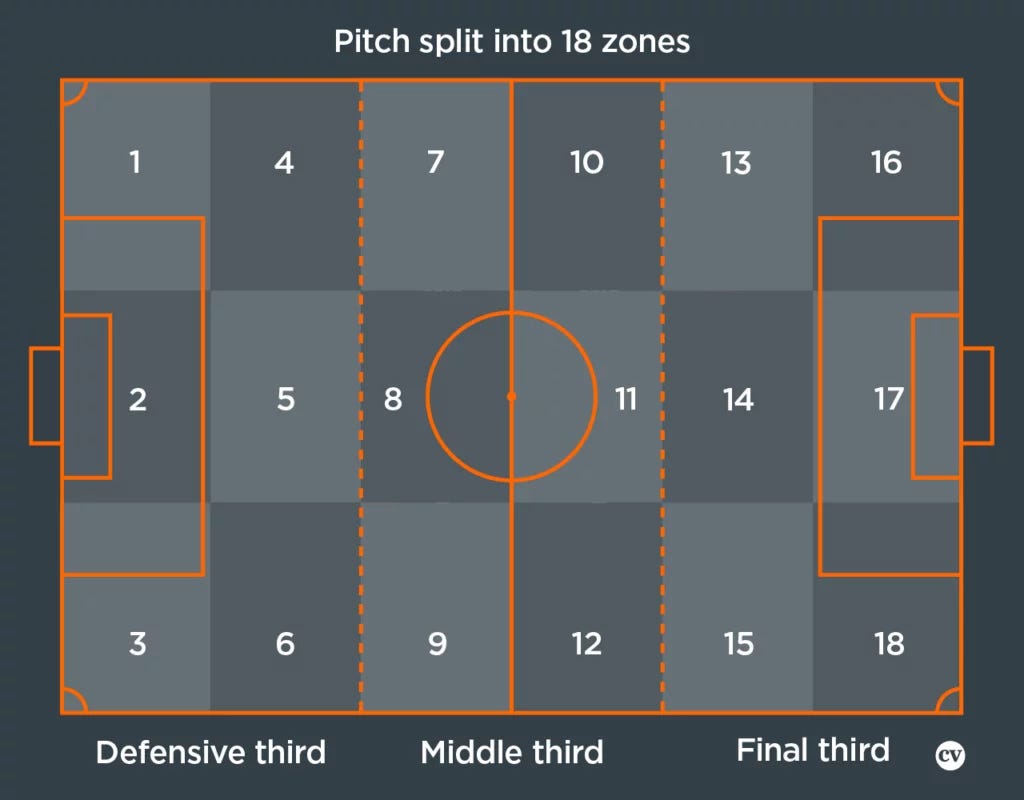
In this article, we only look at passes and what their intention can tell us about playing style and tactics. In the methodology, we will speak more about it, but in essence we use passing direction to establish tactical roles within a game or a series of games.
Data
The data used in this article was retrieved on January 12th, 2025. It consists of event data is courtesy of Opta/StatsPerform. It’s raw data that is manipulated and calculated intro scores and metrics to conduct our research.
I have pulled a smaller sample size to only focus on one team. The specific team that we are going to focus on is Bayern München from the German Bundesliga, season 2024–2025 and is updated until the 10th of January 2025. I have included all players from Bayern Münched that have played in 5 or more games, to make the data more representative.
Methodology
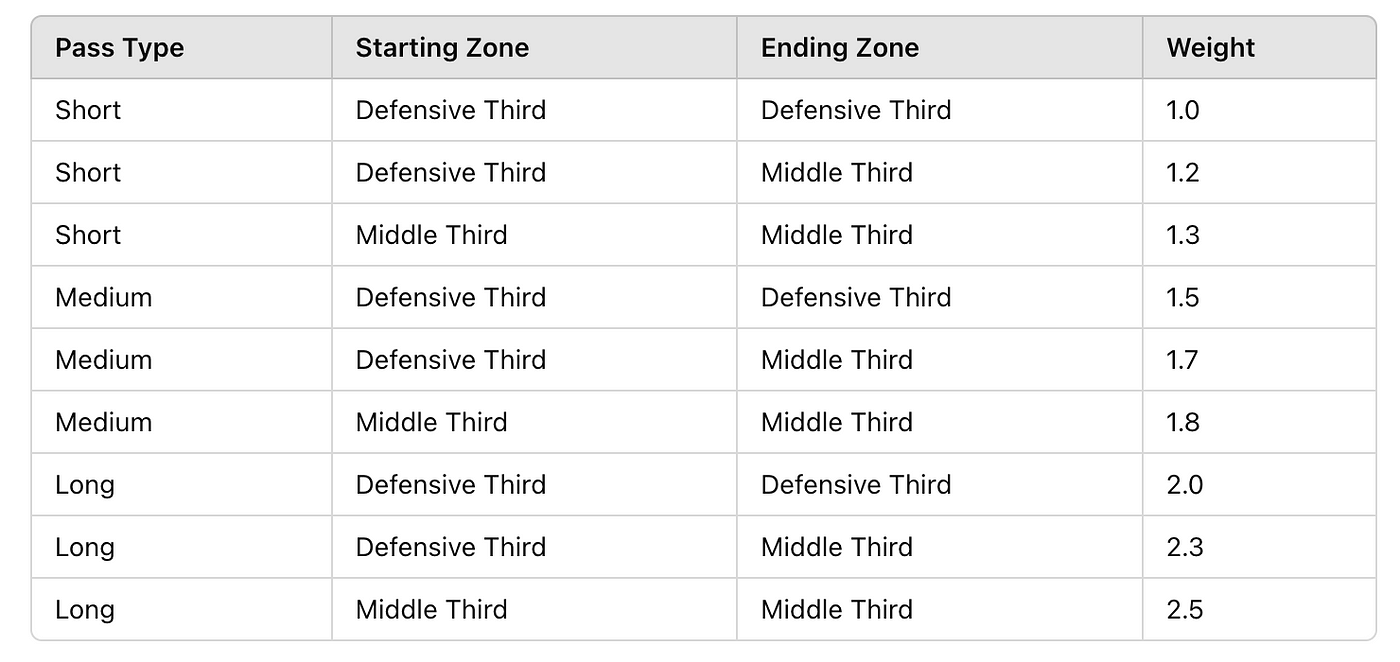
There are a few things we need to do to get from the raw data to our desired metrics. First, we need to qualify each pass in our database and categorise them. Important for this is that we look at intention and so much to success, so the outcome doesn’t play a big role.
We have five different directions a pass can go:
- Forward: A pass where the ball moves predominantly in the positive vertical (y-axis) direction, i.e., toward the opponent’s goal in most contexts.
- Back: A pass where the ball moves predominantly in the negative vertical (y-axis) direction, i.e., toward the passer’s own goal.
- Lateral: A pass where the ball moves horizontally along the field, with minimal forward or backward movement.
- Diagonal: A pass where the ball moves both vertically and horizontally, creating a diagonal trajectory.
- Stationary: A pass where the ball does not move significantly or remains near the initial position.
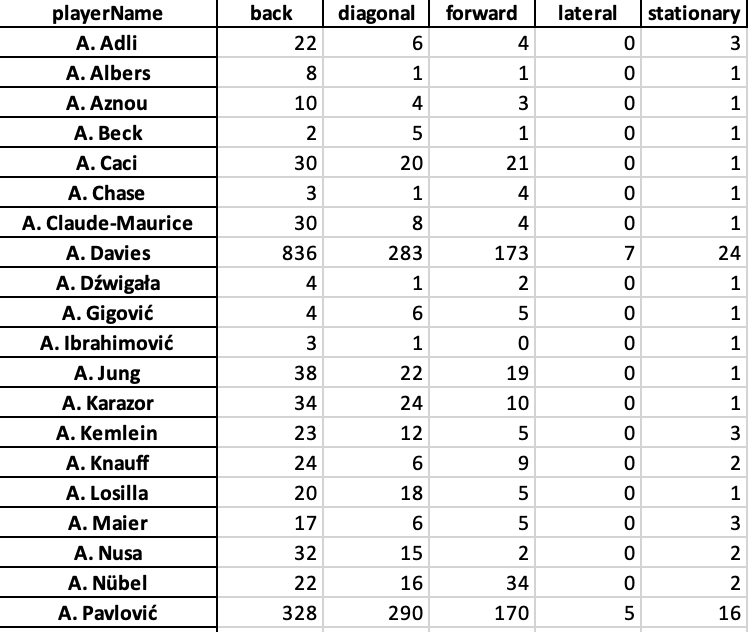
We run the code through Python and convert our initial raw event data into the new count. It will show us the players with the pass directions they have in the database, that will look something like this:
Now we have our pass directions, but the next step is to convert those pass directions into something more tangible, something more actionable. We chose to create new metrics or roles with these given metrics.
We have four different roles:
- Attacker
- Playmaker
- Support
- Defender
Each of these roles is made by looking at pass direction and assigning weights to the calculation of the z-scores. This you can see in the code below.# Calculate z-scores for each direction
z_scores = (direction_counts – direction_counts.mean()) / direction_counts.std()
# Define weights for each direction
weights = {
‘forward’: 1.5,
‘back’: 1.0,
‘lateral’: 1.2,
‘diagonal’: 1.3,
‘stationary’: 0.8
}
# Apply weights to z-scores
for direction, weight in weights.items():
if direction in z_scores.columns:
z_scores[direction] *= weight
# Assign roles based on weighted z-scores
roles = []
for _, row in z_scores.iterrows():
role_scores = {
‘Playmaker’: row.get(‘forward’, 0) + row.get(‘diagonal’, 0),
‘Defender’: row.get(‘back’, 0) + row.get(‘lateral’, 0),
‘Support’: row.get(‘stationary’, 0) + row.get(‘lateral’, 0),
‘Attacker’: row.get(‘forward’, 0) * 1.2 + row.get(‘diagonal’, 0) * 1.1
}
roles.append(max(role_scores, key=role_scores.get))
z_scores[‘role’] = roles
Now, if we run that code — we will not only get the players with their pass directions, but we will get roles too. Roles that will give intention and the numbers will show how close they are to the perfect role. We use z-scored to calculate that.
To create a score that goes from 0–1 or 0–100, I have to make sure all the variables are of the same type of value. In this, I was looking for ways to do that and figured mathematical deviation would be best. We often think about percentile ranks, but this isn’t the best in terms of what we are looking for because we don’t want outliers to have a big effect on total numbers.
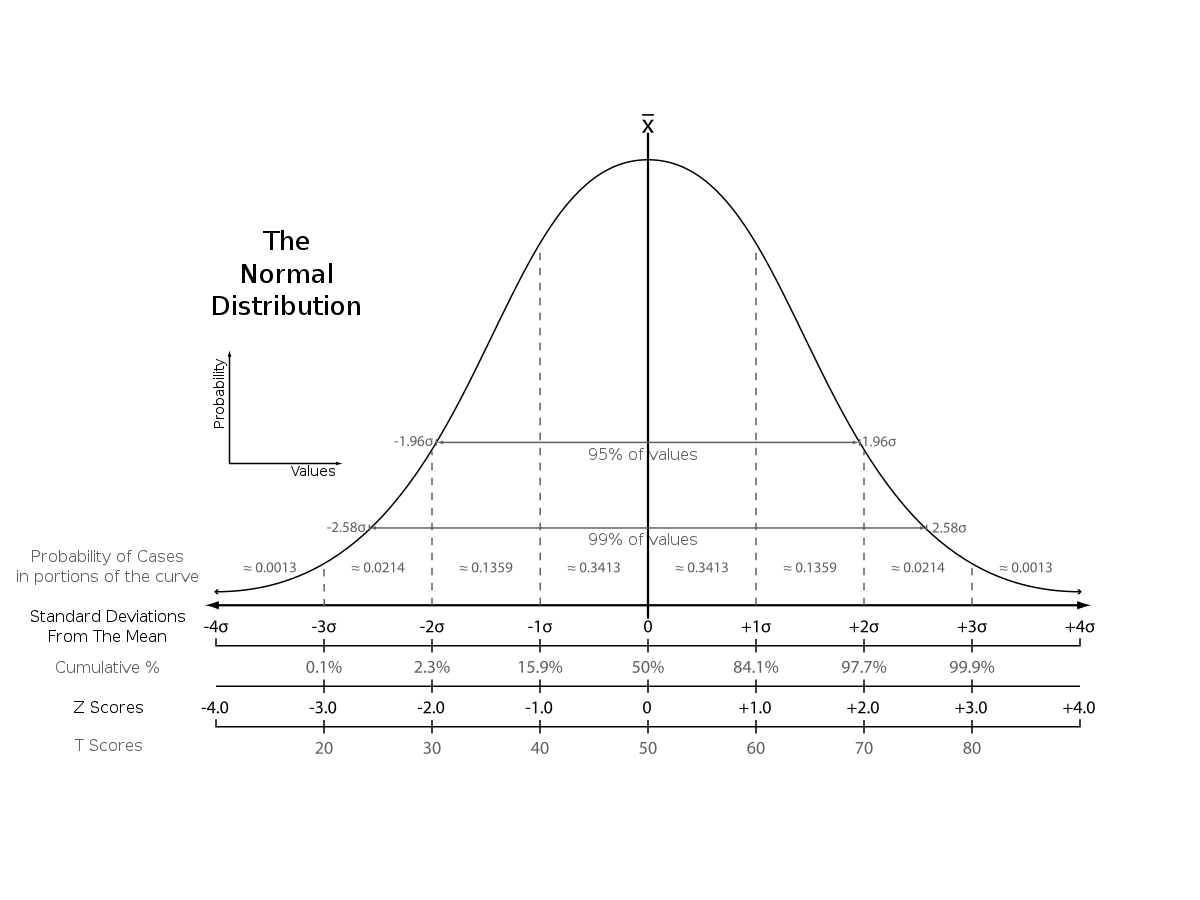
I’ve taken z-scores because I think seeing how a player is compared to the mean instead of the average will help us better in processing the quality of said player and it gives a good tool to get every data metric in the right numerical outlet to calculate our score later on.
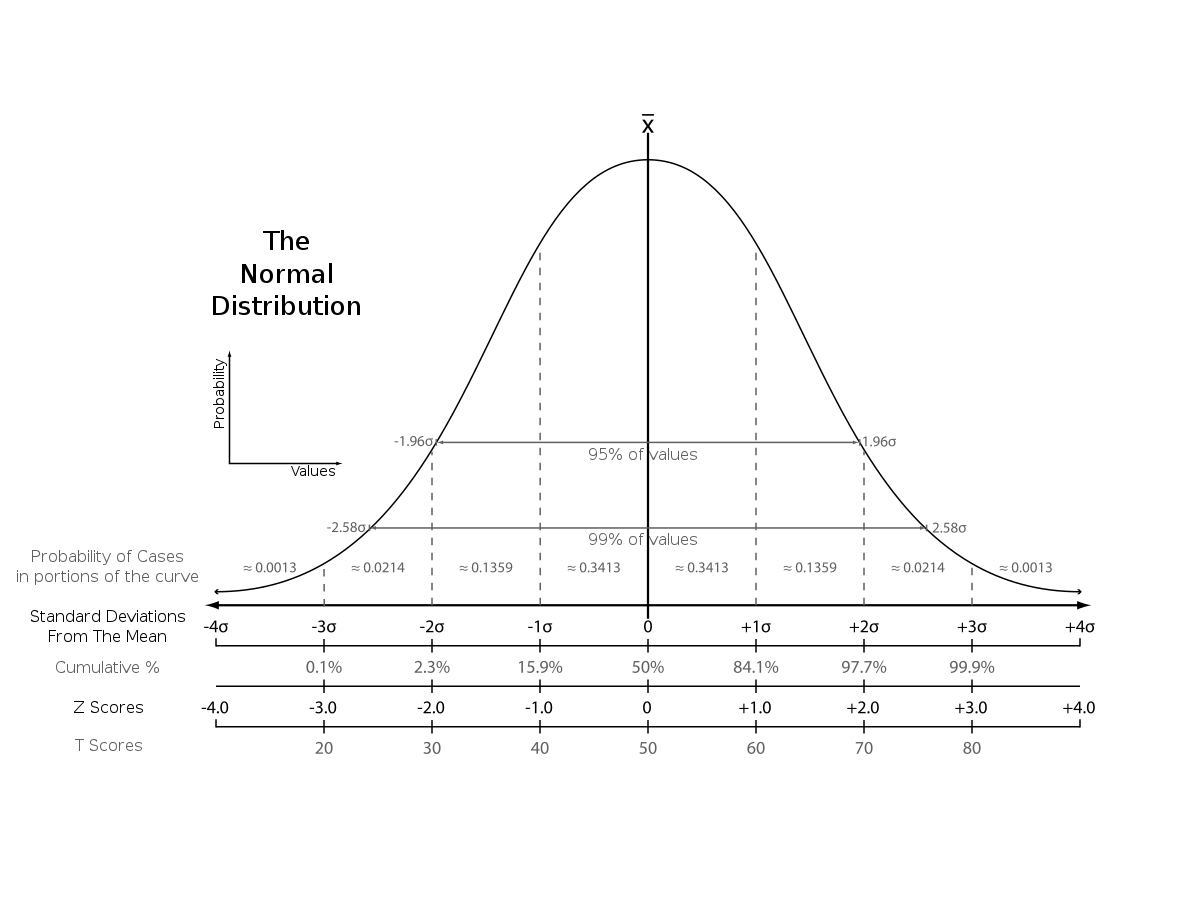
Z-scores vs other scores. Source: Wikipedia
We are looking for the mean, which is 0 and the deviations to the negative are players that score under the mean and the deviations are players that score above the mean. The latter are the players we are going to focus on in terms of wanting to see the quality. By calculating the z-scores for every metric, we have a solid ground to calculate our score.
The third step is to calculate the CTS.
We talk about harmonic, arithmetic and geometric means when looking to create a score, but what are they?
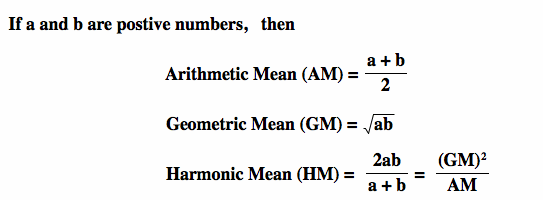
The difference between Arithmetic mean, Geometric mean and Harmonic Mean
As Ben describes, harmonic and arithmetic means are a good way of calculating an average mean for the metrics I’m using, but in my case, I want to look at something slightly different. The reason for that is that I want to weigh my metrics, as I think some are more important than others for the danger of the delivery.
So there are two different options for me. I either use filters and choose the harmonic mean as that’s the best way to do it, or I need to alter my complete calculation to find the mean. In this case, I’ve chosen to filter and then create the harmonic mean.
This leaves exactly what we want. Every pass direction has its z-scores and based on those intentions, we can give roles to the players which they are most likely to fit.
Analysis
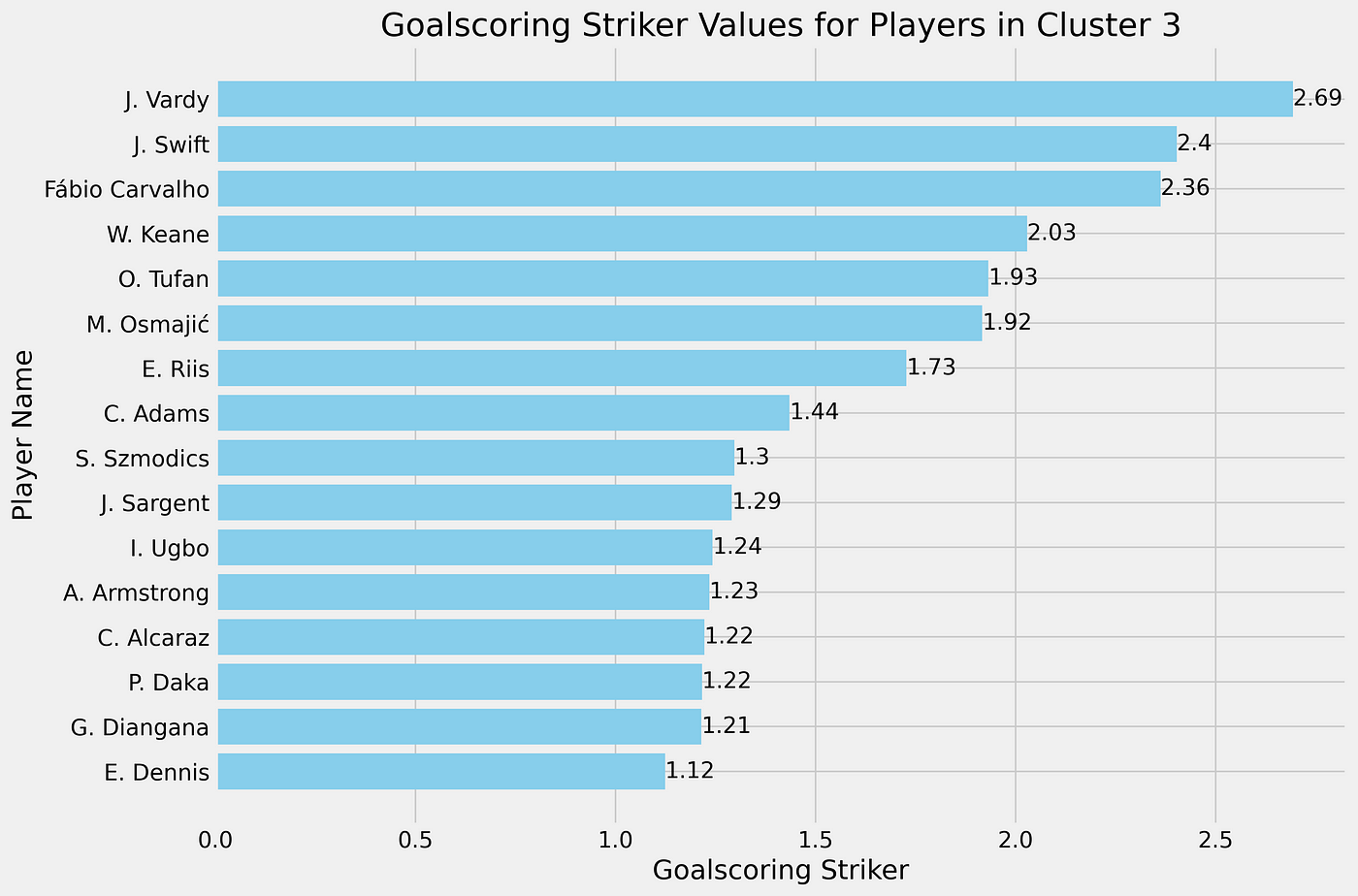
Now that we have all the data we want, let’s look at the most common profiles/roles in these games:
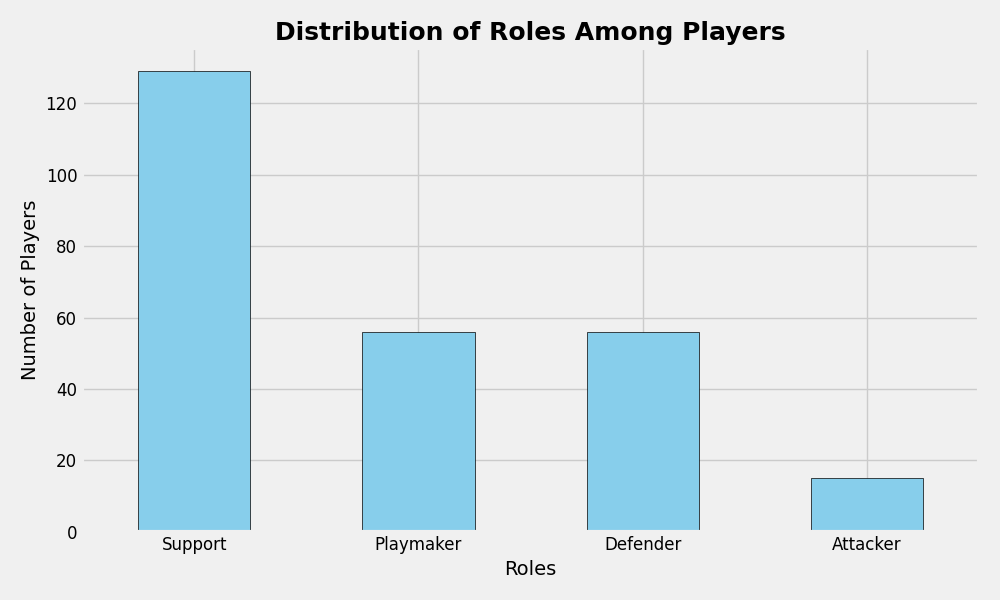
As you can see, most of the players have a support role, followed equally by playmaker and defender, while attacker is the lowest. When we look at the roles there are two more attacking roles and two more defensive roles
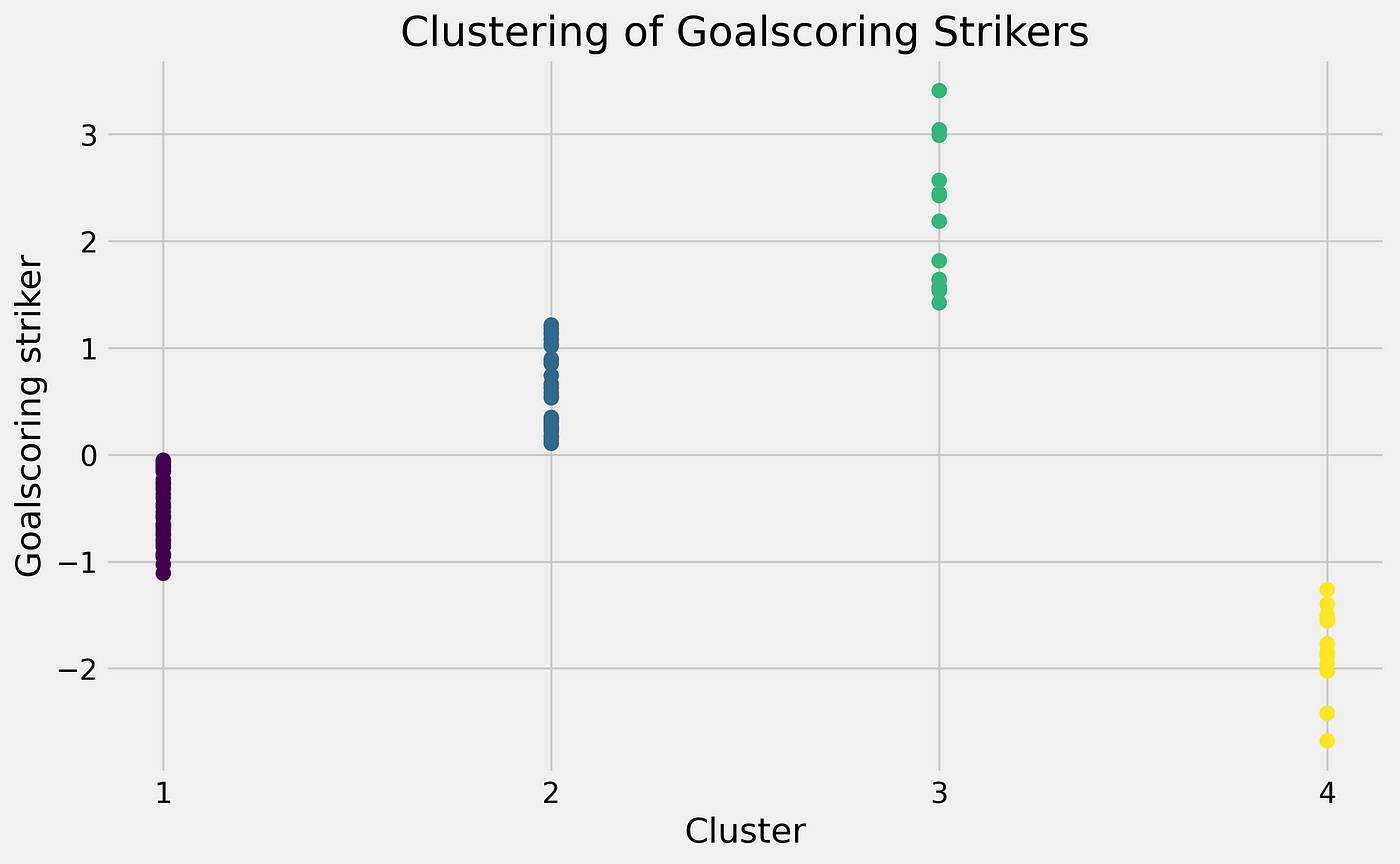
The next step is to combine the roles and create a scatterplot that shows us how good a player is in the defensive and attacking metrics:
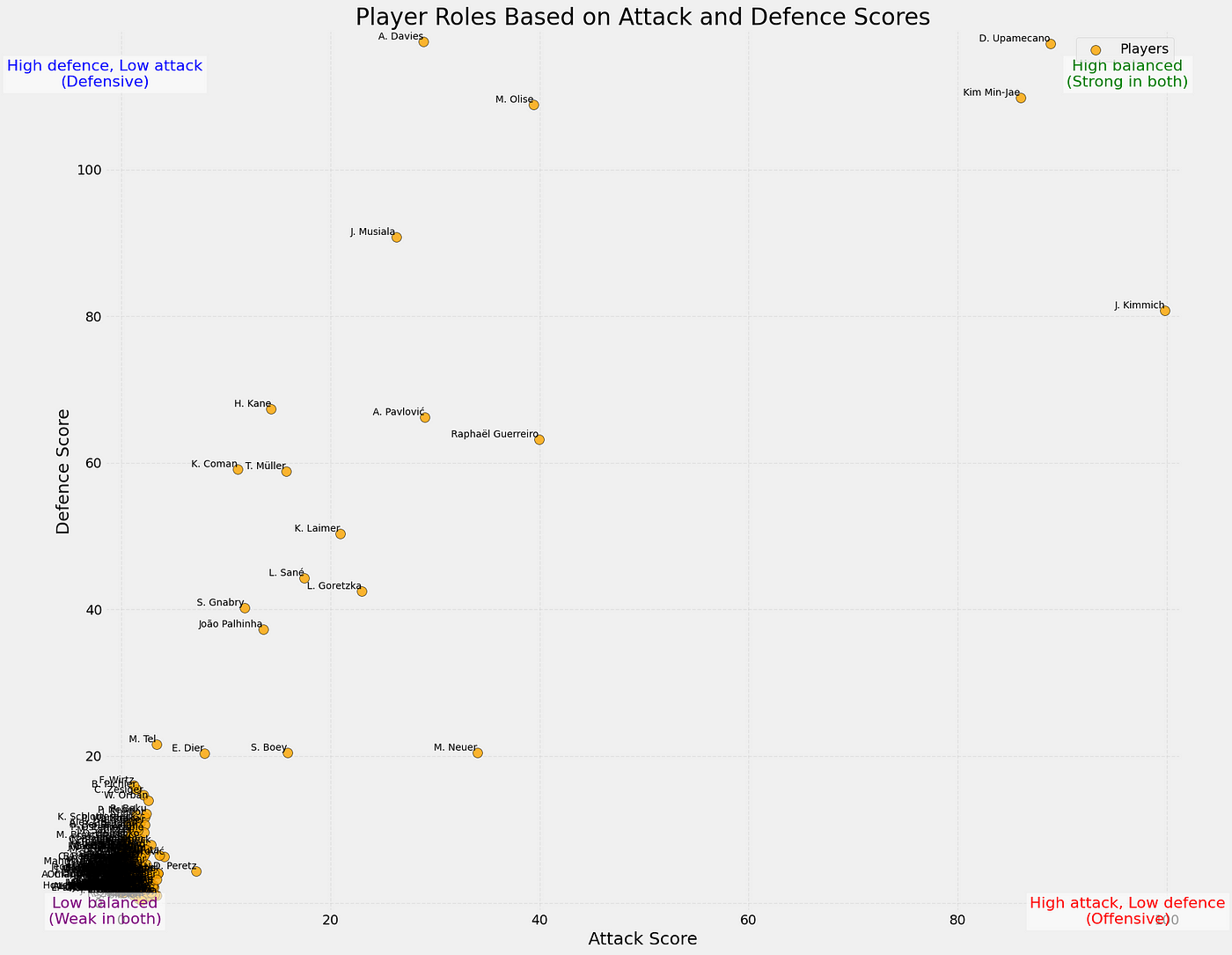
In the scatterplot above you can see how the players perform according do their attacking and defensive scores (0–100). You can also see the tendencies in the corners of the plot, showing what values are assigned to them.
What’s interesting in this case is that the players with the highest attacking score or contribution from their passing, are the defenders. It’s not surprising as they always will pass the ball up the pitch, while attackers will need to be more conservative in their passing as they are also tasked with maintaining possession.
Final thoughts
This framework provides a practical way to analyse player performance by turning pass directions and weighted metrics into clear roles like Playmaker, Attacker, Defender, and Support. It simplifies complex player behavior into easy-to-understand visuals, like scatterplots and bar charts, making it easier for coaches and analysts to see how players contribute. Plus, the flexibility of this system means it can be adapted to other sports or fine-tuned to fit specific strategies.
That said, there’s room to make it even better. The weights used are static and don’t adjust to changing game situations, and the roles might oversimplify players who excel in multiple areas. Adding more context, like player positions or game situations, could make the results even sharper. Overall, this framework is a great starting point for understanding player roles and opens up plenty of opportunities to refine and expand the analysis.