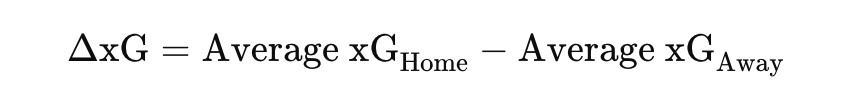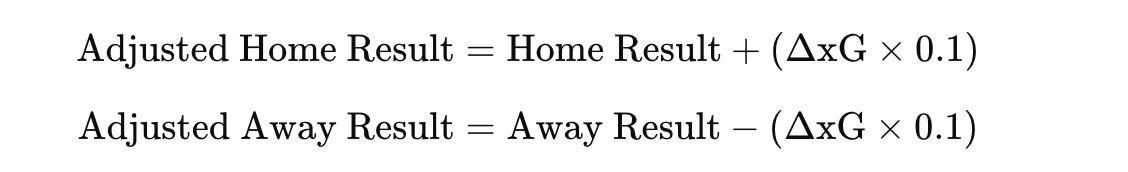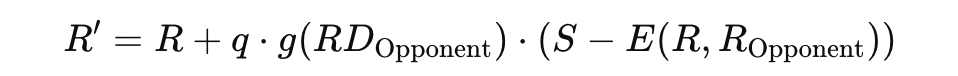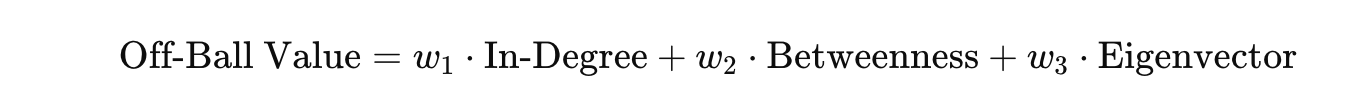People often ask me what gives me the most joy about working in football and I honestly can remember when I gave the same answer twice. It’s an incredibly dynamic world, and I love so many aspects of it. Sometimes it’s also that I just love everything and that’s part of my shortcomings. However, I missed writing about specific scouting topics and I decided to combine mathematical concepts with finding a particular player. Let’s look at player similarities.
Player similarities can give us an insight not only into the player of similar quality but also give us an indication of the similar playing style a player might have.
In this article, I will look at similar players to Mohammad Salah from Liverpool playing in the Premier League. Not only will I find some similar players, but I will be using three different ways of doing that:
Cosine Similarity
Euclidean Distance
Pearson Correlation Coefficient.
These three concepts will be explained prior to the actual analysis of this article.
Data
For this analysis, I’m using Wyscout data from the 2024–2025 season which consists of the Premier League. These have been collected on December 27th, 2024 so some of the data can be outdated as of when you are reading this article.
This can obviously be done with other data sources such as Statsperform/Opta, Statsbomb and many others, but these are the sources I’m using. I’m filtering the players for attackers who have played at least 500 minutes to make it all a bit more representative.
Cosine Similarity
Cosine similarity measures the similarity between two vectors by computing the cosine of the angle between them. It is calculated by taking the dot product of the vectors and dividing by the product of their magnitudes. The resulting value ranges from -1 to 1, though in most practical scenarios (especially in text analysis), it ranges from 0 to 1. A higher value indicates greater similarity.
Cosine similarity is scale-invariant, meaning that scaling a vector does not affect its similarity. As seen above, it is about the angle rather than the distance of the two points. It is widely used in natural language processing, information retrieval, recommendation systems, and clustering for measuring the resemblance between data points.
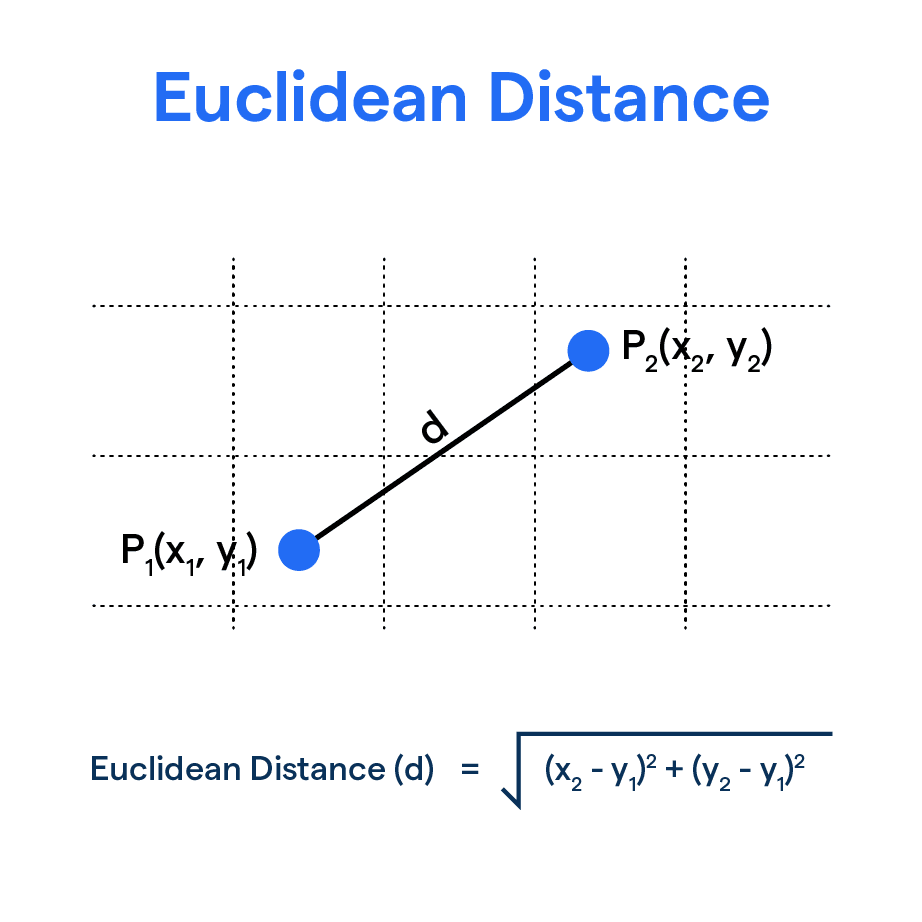
Euclidean Distance
The Euclidean distance is a fundamental metric in mathematics and data science that measures the straight-line distance between two points in Euclidean space. It is derived from the Pythagorean theorem, which states that the square of the hypotenuse of a right triangle equals the sum of the squares of the other two sides. The Euclidean distance is the square root of the sum of squared differences between corresponding coordinates.
This measure captures how far apart two points are, which makes it useful in various tasks such as clustering, classification, and anomaly detection. Unlike some other distance metrics, Euclidean distance is sensitive to scale and does not directly account for direction.
Pearson Correlation Coefficient
The Pearson correlation coefficient is a statistical measure that quantifies the strength and direction of the linear relationship between two continuous variables. Mathematically, it is defined as the ratio of the covariance of the two variables to the product of their standard deviations.
Its value ranges from -1 to +1, where -1 indicates a perfect negative linear correlation (as one variable increases, the other decreases at a proportional rate), +1 signifies a perfect positive linear correlation (both variables move together in the same direction proportionally), and 0 indicates no linear relationship. Because it captures only linear relationships, a high or low Pearson correlation does not necessarily imply a cause-and-effect relationship or any non-linear association.+——————-+——————————–+———–+—————–+—————————+ | Metric | Definition | Range | Scale | Key Usage | | | | | Sensitivity | | +—————————————————————————————————————+ | Cosine Similarity | Cosine of angle between vectors | -1 to +1 | Scale-invariant | Text analysis, | | | | | | recommendations | +—————————————————————————————————————+ | Euclidean Distance| Straight-line distance | 0 to +∞ | Scale-sensitive | Clustering, | | | in n-dimensional space | | | nearest-neighbor | +—————————————————————————————————————+ | Pearson | Measures linear | -1 to +1 | Scale-invariant | Stats, data science | | Correlation | relationship | | | | +——————-+———————————-+———–+—————–+—————————+
In the table above you see the three different metrics compared to each other. I wanted to show and compare these different ways of looking at similarities as it will lead to different results in actually finding similar players. Let’s have a closer look.
Similar players
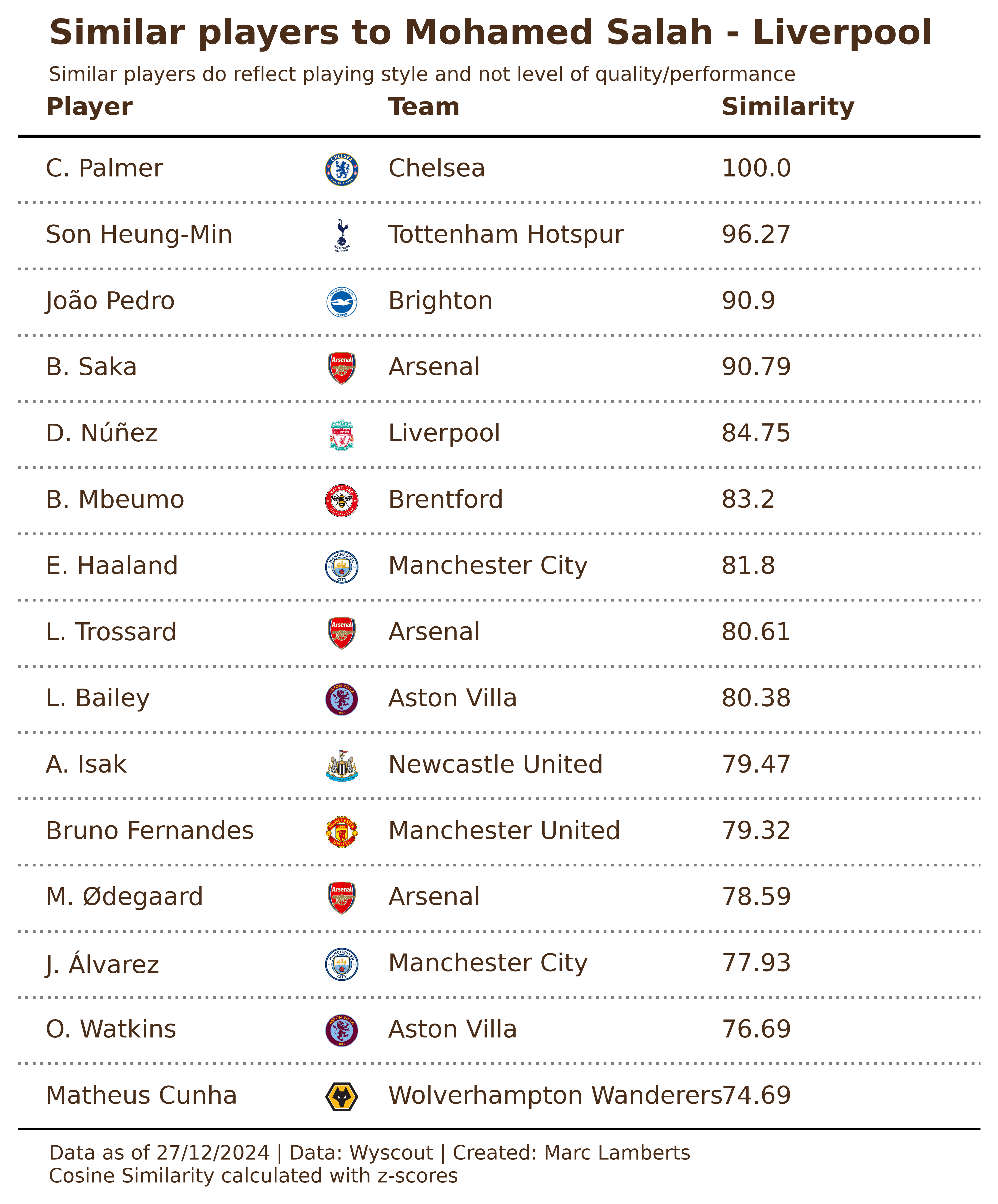
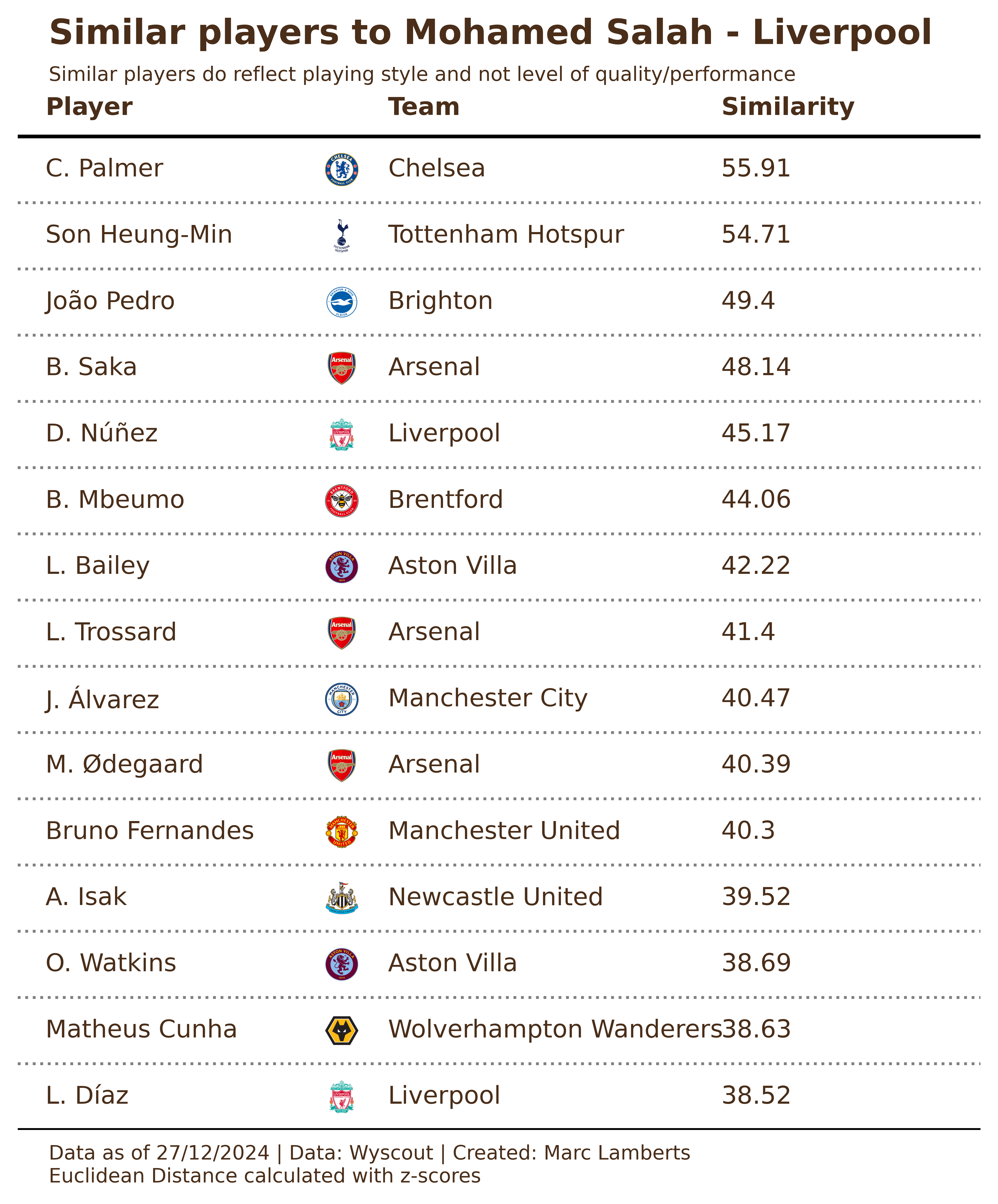
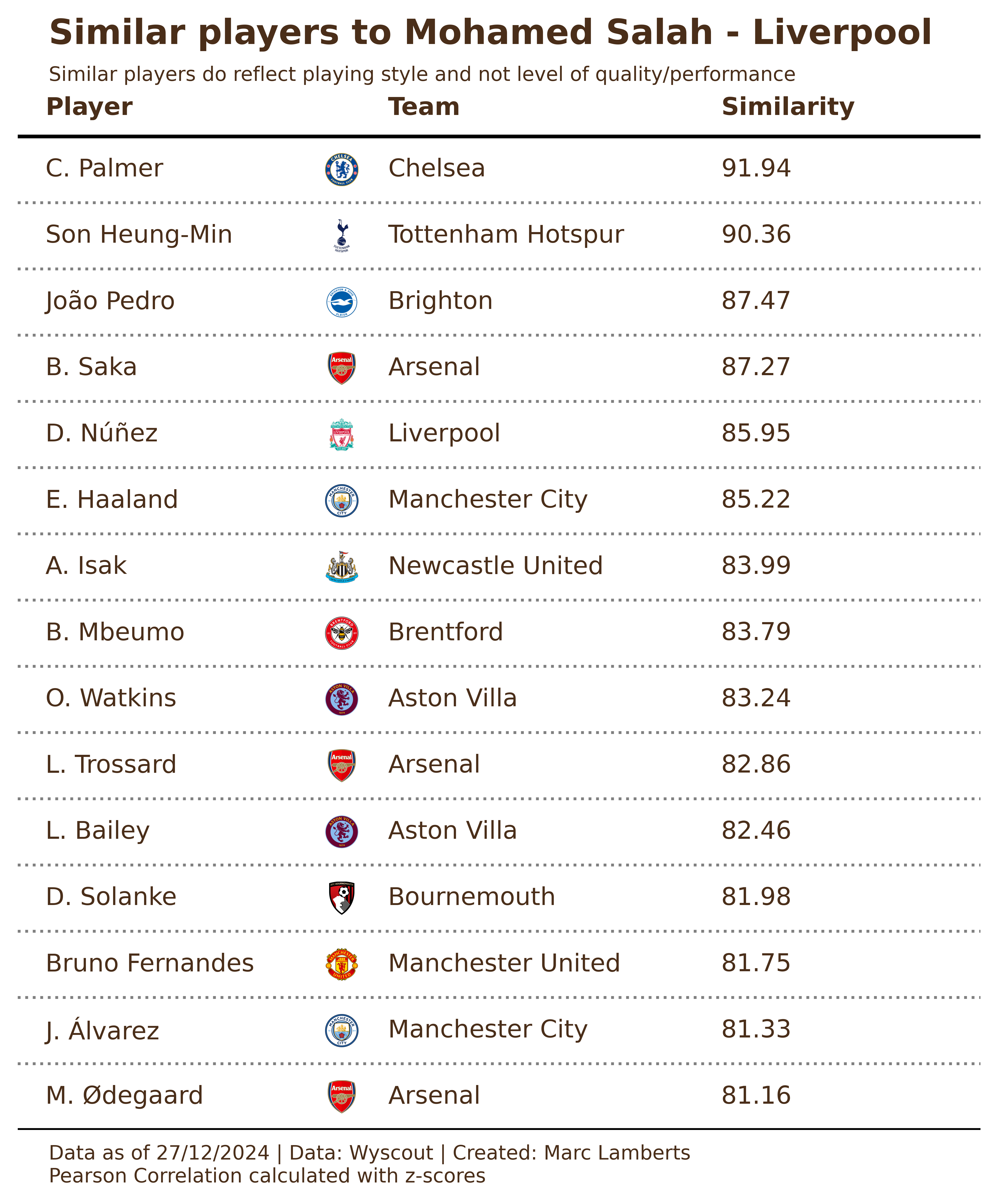
As said above, we will look at the Premier League to find similar players for Mohammad Salah based on playing style and intention. Using the three different methods we get these results:
The first things that we can conclude from this is that there are different ways of calculating similarity and these numbers are different. The similarities in Cosine Similarity are bigger in the distance between players, while with Pearson Correlation the distances are smaller but there are less big similarities. The Euclidean distance works with different ways of counting similarities, so you mostly see the same players, but the similarity number is much much lower.
The second thing you can see is that it lists almost the same players, however, the ranking shifts. Haaland for example is the 7th most similar player in Cosine Similarity, not in the top 15 with Euclidean Distance and 6th with Pearscon Correlation. If you base your findings on rankings, it is important to stress that the method of calculation will manipulate the data and influence decision-making.
This year would be the year that I would immerse myself in set pieces. I know that is something I’ve said a lot and it was one of my goals this year — but life has a funny way of disrupting all plans. Now, this year I’ve done a lot on metric development and before the year closes I wanted to share one last metric development/methodology with you that concerns set pieces.
But, I want to do a final one that goes further and proceeds on the thought pattern of the Individual Header Rating (IHR). I have looked at an individual level what players can contribute in terms of headers, but how do teams rate in set pieces? That’s what I’m trying to illustrate by introducing SPER. A way of rating Set Piece Expected Goals Differences between teams.
Why this metric for set piece analysis?
There isn’t a great necessity for this specific metric. One of the reasons is for me to try and make a power ranking based on expected goals for set pieces. However, with this insight we can create a way of rating team’s on their expected goals performance on set pieces and evaluate whether to rely on them.
In other words, with this metric, we can draw conclusions on how well teams are doing with their set piece xG. This can lead us to a few conclusions as to why teams need to rely on their set piece routines or to improve their open play, as to spread their win chances.
With this metric, we can combine this with the Individual Header Rating and gain meaningful analysis for set pieces, both on individual and team level.
Data collection and representation
The data used for this project comes from Opta/Statsperform and was collected on Thursday 18th of December 2024. All of the data is raw event data and from that XY-data, all the metrics have been developed, plotted, manipulated and calculated.
The data is from the Eredivisie 2024–2025 season and both contains match-level data as well as season-level data. There aren’t any filters used for value, but this is something that can be done in the next implementation of the score, as I will explain further on in this article.
This focuses on how teams are doing so that’s why the set piece xG are generated for each team and not for the individual players. We can split them for players, but it will not be as representative. The xG generated from set pieces often is the consequence of a good delivery as well, which would be nullified if we look at it from an individual angle.
There are different providers out there offering the XY-data, but I am sticking to Opta data for event data as all my research with event data has been done with Opta and therefore the continuity will improve the credibility of this work in line with my earlier work.
What is categorised as set piece?
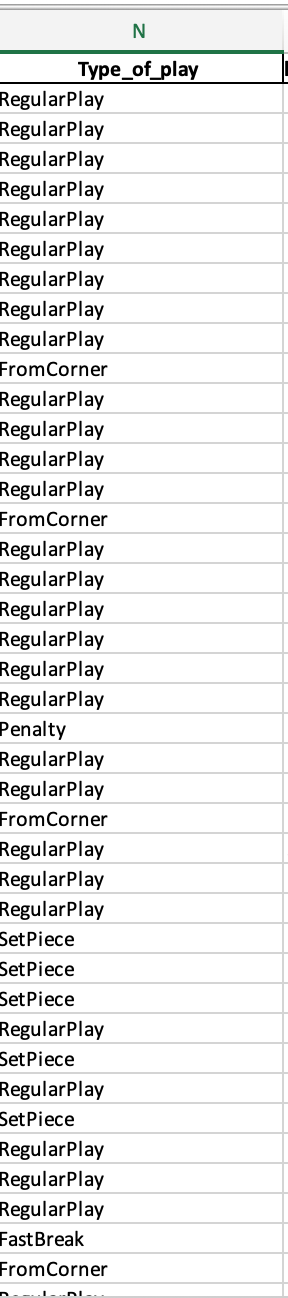
This might seem like a very straightforward question, but one we need to talk about regardless. In the data there are different filters for our xG:
So, we need to make a distinction between different plays. We will focus on set pieces, but as you can see there are different variables:
SetPiece: Shot occurred from a crossed free kick
FromCorner: Shot occurred from a corner
DirectFreeKick: Shot occurred directly from a free kick
ThrowinSetPiece: Shot came from a throw-in set piece
I am excluding penalty. By all means it is a set piece, but the isolation of the play means that it’s such a big impact on the expected goals, that I will exclude it. It doesn’t say anything about the quality of play, but rather about the quality of kicktacking.
Methodology
There are a few steps I need to take before I get the SPER from my original raw data. The first step is to convert the shots I have into shots with an expected goal value. Which shots are listed?
Miss: Any shot on goal which goes wide or over the goal
Post: Whenever the ball hits the frame of the goal
Attempt saved: Shot saved — this event is for the player who made the shot.
Goal: all goals
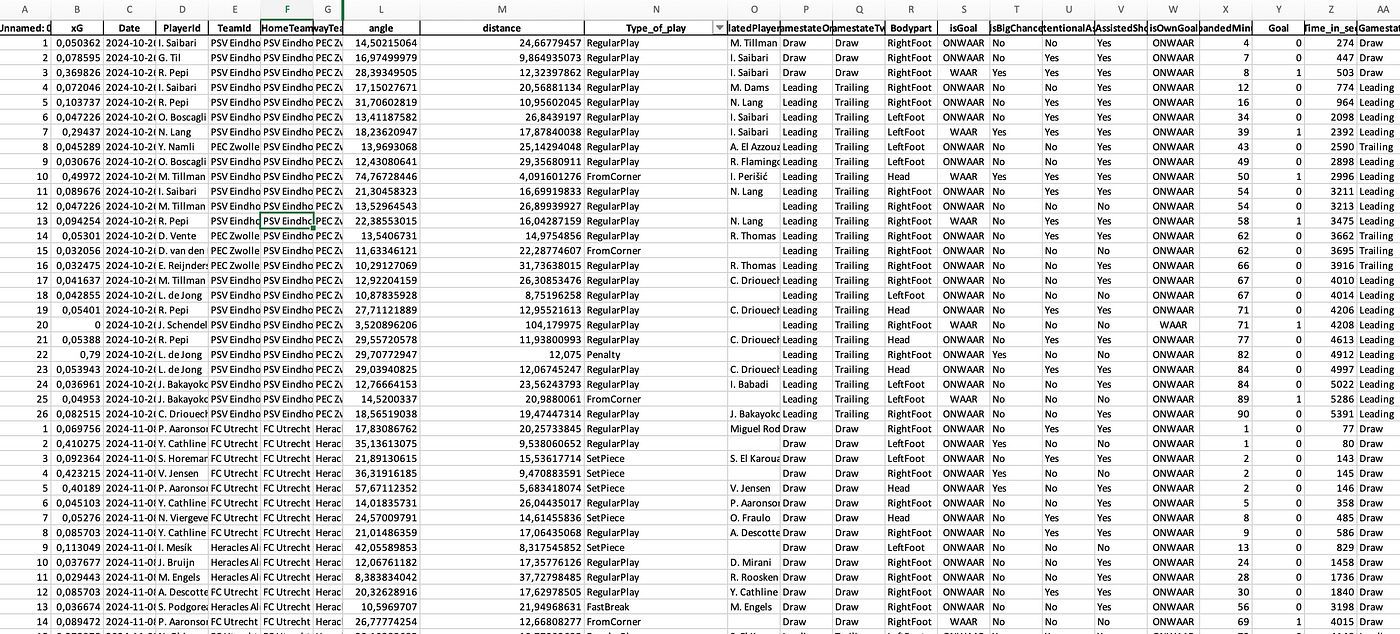
We take these 4 events and convert them to shots with added value, by putting them through my own xG model that’s trained on 400.000 shots in the Eredivisie. We then get an excel/csv file like this:
This is the core we are working with, but the next step is to also calculate and generate what that means per game for each side. This will add to the xG values, but also win chance in % and the Expected Points given based on that expected goals.
So, now I have the two Excel files that form the base of my methodology and calculation. From here on, I’m going to focus on creating a new rating: SPER.
That has to happen in Python, because that’s my coding language of choice, and will need a few things.
This analysis combines match results and expected goals (xG) data using the Glicko-2 rating system to dynamically evaluate team performance. Match outcomes are determined by comparing xG values of home and away teams. A win, draw, or loss is assigned based on xG values:
Additionally, xG data for specific play types, such as “FromCorner” and “SetPiece,” is filtered and averaged for each team.
The scaling factor (0.1) ensures the adjustment is proportional and keeps outcomes between 0 and 1.
The Glicko-2 system updates team ratings after each match using adjusted outcomes. Each team has a rating (R), a rating deviation (RD), and a volatility (σ). Updates are based on the opponent’s rating and RD, incorporating the adjusted match outcome (S). The system calculates the new rating as:
This is obviously for all the technical mathematicians out there, however, this is the calculation that has been done in Python, but via code. By converting this into Python code, we get a ready to use excel that we can use in the analysis.
Analysis
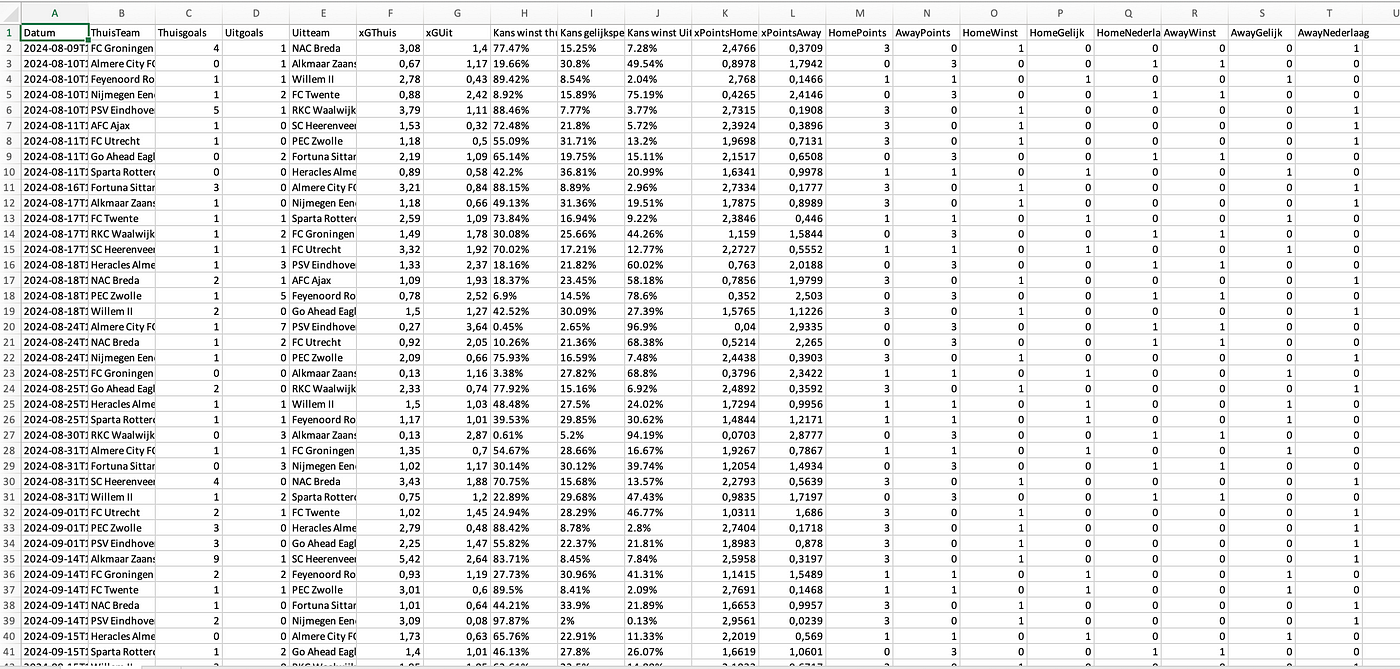
With the data in the excel file, I know have ratings for every matchday for every team in the Eredivisie. It shows how well every team is doing and how they are progressing over the first half of the 2024–2025 season.
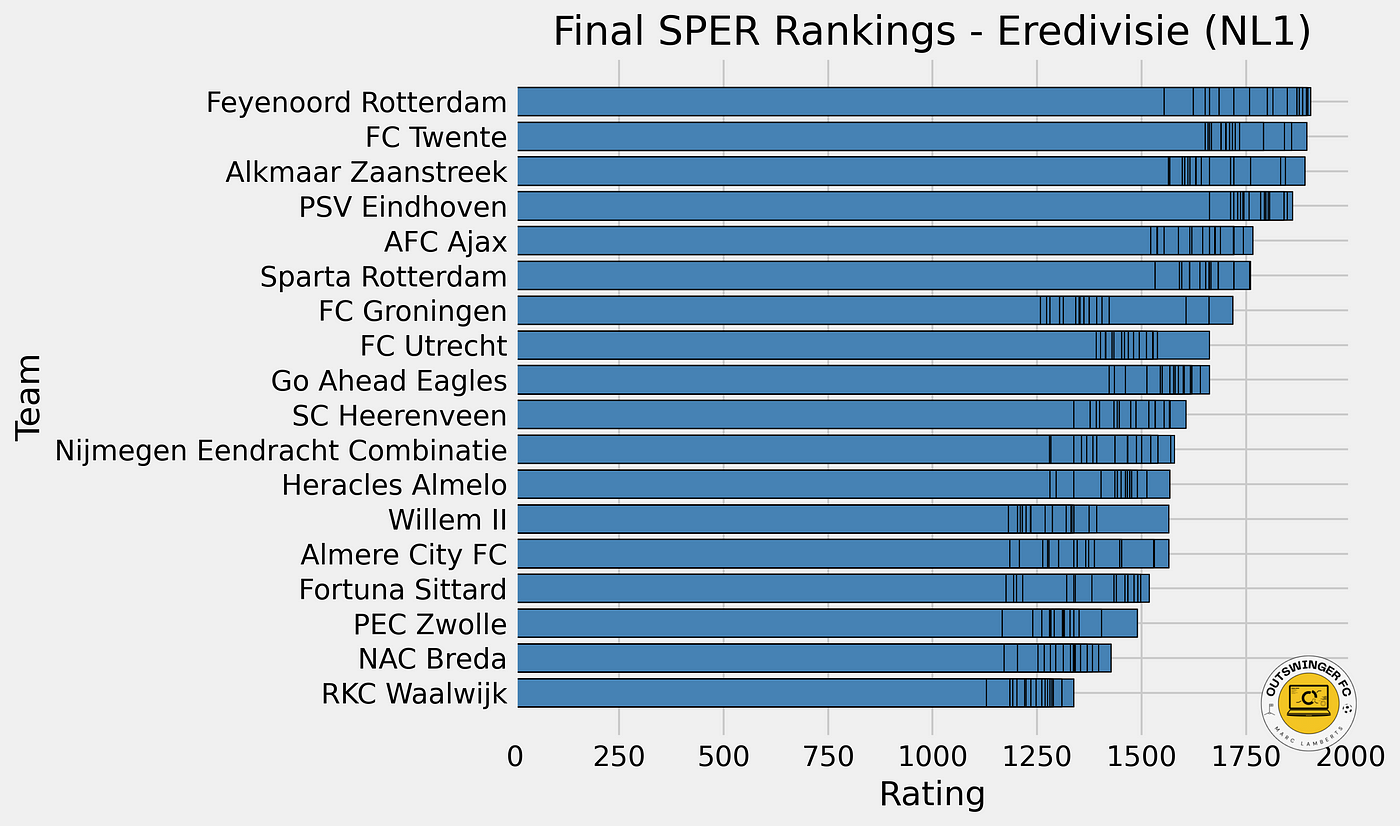
In the bargraph above you can see the final ratings for the Eredivisie with an average included. In the bargraph previous ratings are also included for every team. Feyenoord, FC Twente, AZ, PSV and Ajax are the best teams in terms of SPER. Fortuna Sittard, PEC Zwolle, NAC Breda and RKC Waalwijk are the worst.
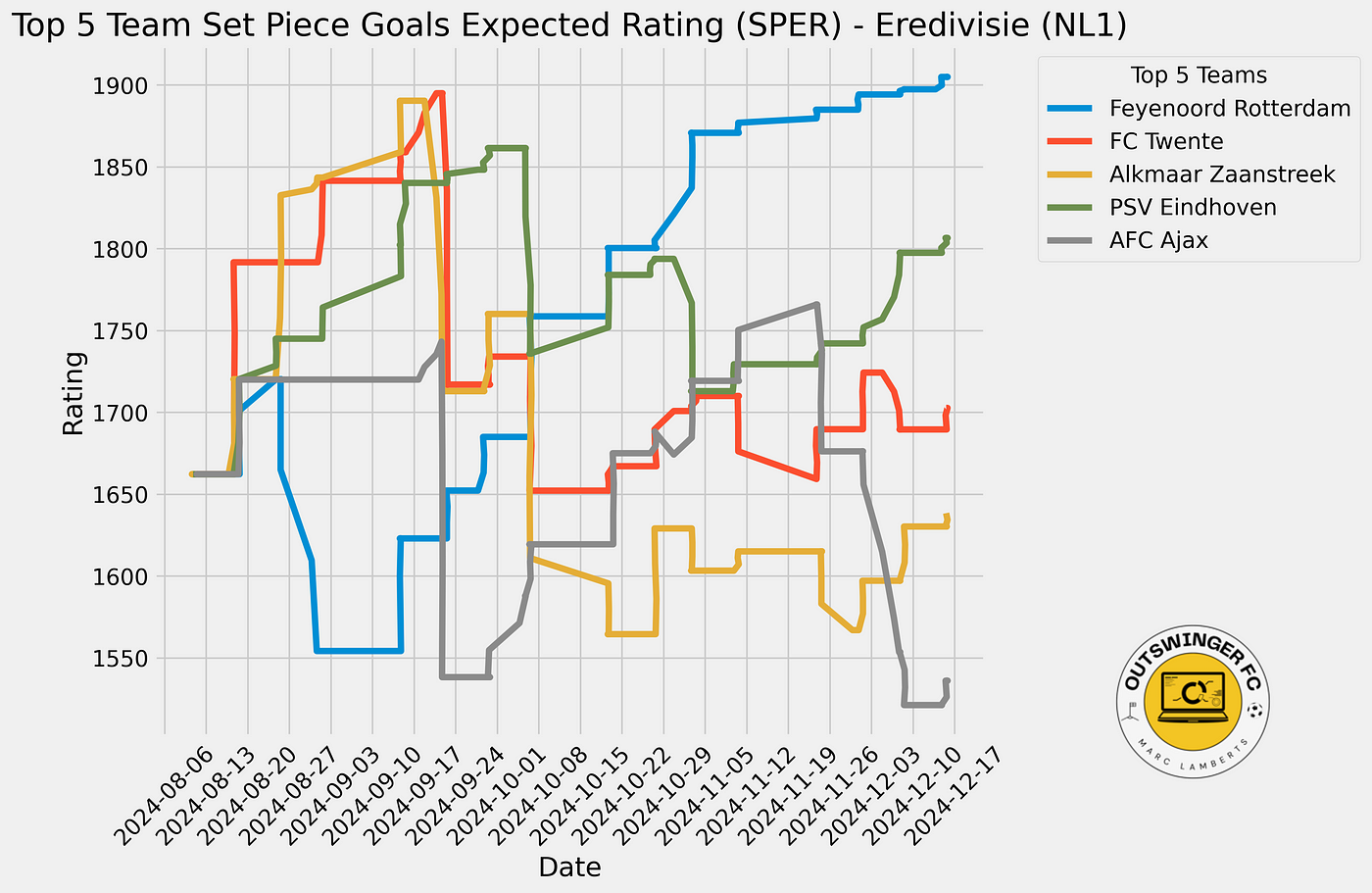
In the line graph above, you can see how the ratings evolve over the course of the season for the top 5 teams in the Eredivisie for SPER. As we can see Feyenoord steadily becomes better, while PSV jave a more interesting trajectory with starting high and climbing again. Ajax really sinks in the last few weeks.
Final thoughts
The Glicko-2 scoring system provides a clear way to rank Eredivisie teams by combining match results and average expected goals (xG). It adjusts ratings dynamically, considering form and opponent strength, while xG adds context by reflecting goal-scoring chances. This approach gives a better understanding of team performance than traditional standings. However, its accuracy depends on reliable xG data and the chosen scaling factor for adjustments. Overall, the system is practical for tracking team progress and comparing strengths, offering useful insights for fans and analysts.
This might be my best and scariest project up to date. Scary because it can be full of flaws, but also best because I feel this will change something in the way we approach passing networks. Not that I think I will innovate the analytics space, but because I have been trying to find a way to create something meaningful from passing networks away from the aesthetics on social media. Because, I’m a firm believer we can create something meaningful from it and gather valuable information, you just need to know where to look and what the aim is.
In this article, I will show you a way that you can use to create off-ball value from passing networks by creating metrics from it and then going to an analysis that will lead to calculations for an impact store. That sounds very vague, but it will become more clear — I sure hope so at least lol — at the end of this article. It will have some logical steps to ensure it remains transparent at all times.
Why this development in passing network analysis?
I eluded to the fact a little bit, but the reason for this analysis is predominantly selfish. I wanted to see if I could create something meaningful from passing networks and test myself to create an off-ball value from event data. The reason for that is that I believe we have incredible data on how valuable possession/actions are with the ball, but far too few without the ball.
The next step for me is to show that with an out of the box thinking, there can open a world that offers much more metrics and paths for data analysis, beyond the aesthetically pleasing passing networks we have seen on social media — which I’m guilty of as well — which don’t add a whole lot. So, I wanted to challenge myself and see what we can extract from the passing network interconnectivity and calculations to develop new metrics and work with that.
Data collection and representation
The data used for this project comes from Opta/Statsperform and was collected on Saturday 14th of December 2024. All of the data is raw event data and from that XY-data, all the metrics have been developed, plotted, manipulated and calculated.
The data is from the Eredivisie 2024–2025 season and both contains match-level data as well as season-level data. There aren’t any filters used for value, but this is something that can be done in the next implementation of the score, as I will explain further on in this article.
There are different providers out there offering the XY-data, but I am sticking to Opta data for event data as all my research with event data has been done with Opta and therefore the continuity will improve the credibility of this work in line with my earlier work.
Passing networks: what are they?
American Soccer Analysis (ASA) said it quite clearly for me as follows:
“The passing network is simply a graphic that aims to describe how the players on a team were actually positioned during a match. Using event data (a documentation of every pass, shot, defensive action, etc. that took place during a game), the location of each player on the field is found by looking at the average x- and y-coordinates of the passes that person played during the match. Then, lines are drawn between players, where the thickness — and sometimes color — of each line signifies various attributes about the passes that took place between those players.
The most common and basic style of passing network simply shows these average player locations and lines between them, where the thickness of the line denotes the amount of passes completed between each set of players.”
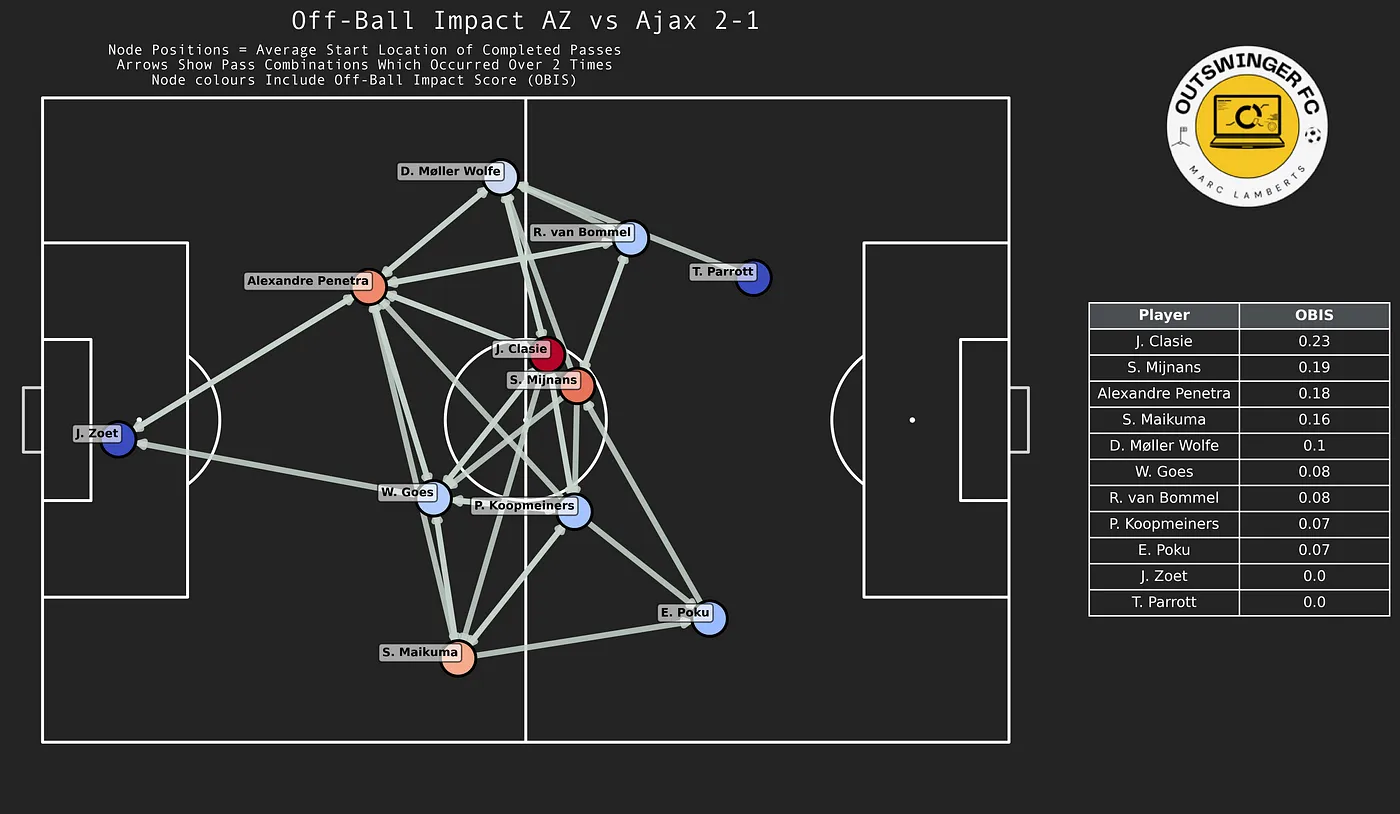
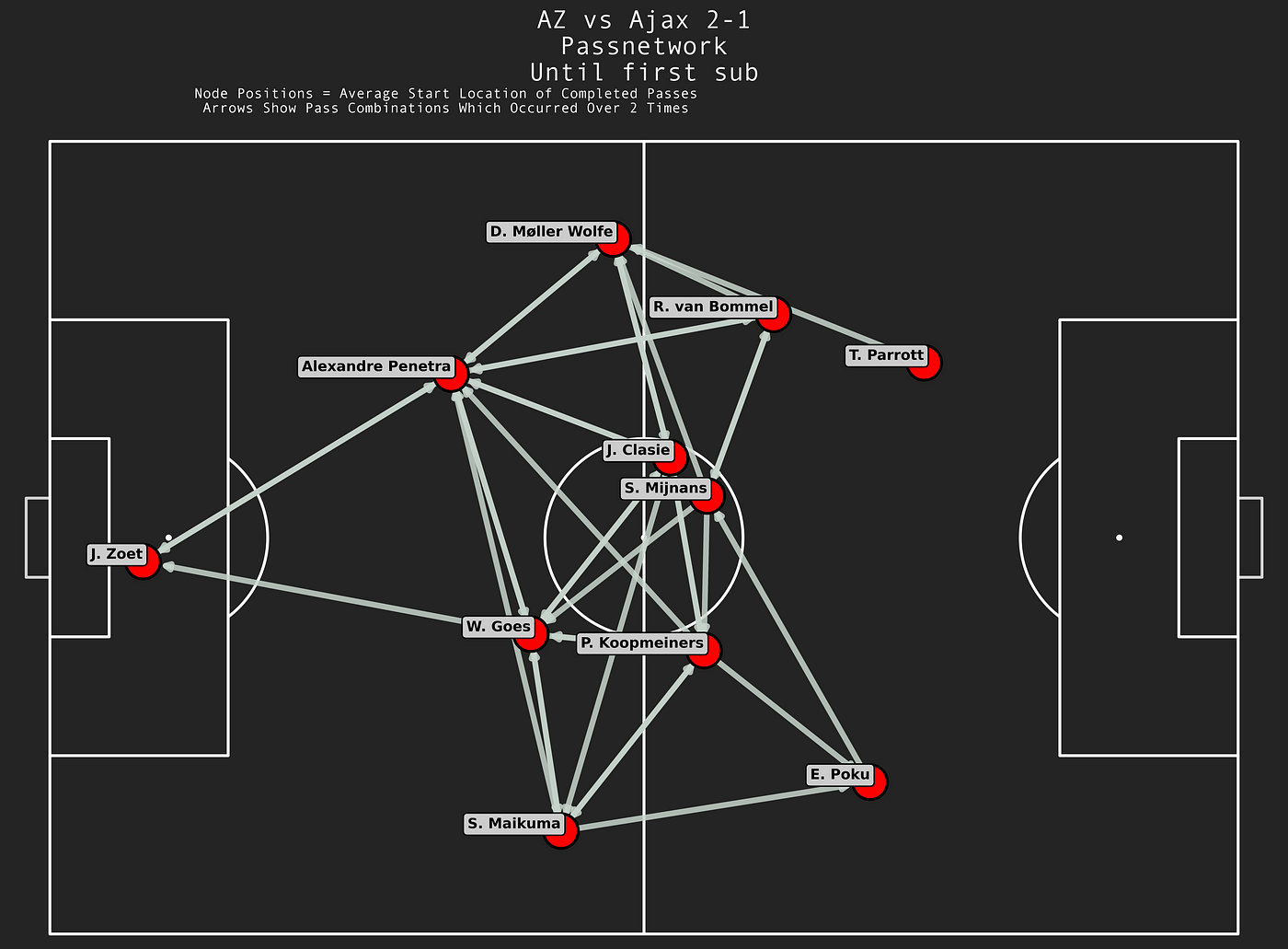
In the image above, I’ve created a passnetwork on a pitch from the game AZ Alkmaar vs Ajax 2–1 (December 8th, 2024) and it shows AZ. Now this shows the combinations and directions of the passing combinations, including the average positions.
This is something we see a lot in articles and social media and data reports, but we want to add value to this. Sometimes this happens by any type of value: Expected Threat (xT), Expected Goal Chain, Goals added (G+) or On-Ball Value (OBV). This gives us more meaning and context about the networks, but in my opinion it’s quite limited in the way it tells us about value away from possession. These are possession-based values.
Methodology Part I: Creating metrics from passing networks
So in the passing network we have calculated the average positon of the 11 starters per team and what the passing combinations are. This is now visual, but we want to take a step back and see a few different things we can create into metrics:
In-degree centrality: The total weight of incoming edges to a player (i.e., the number of passes they received).
Out-degree centrality: The total weight of outgoing edges from a player (i.e., the number of passes they made).
Betweenness centrality: Measures how often a player lies on the shortest path between other players in the network.
Closeness centrality: The average shortest path from a player to all other players in the network.
Eigenvector centrality: Measures the influence of a player in the network, taking into account not just the number of connections they have but also the importance of the players they are connected to
Clustering coefficient: Measures the tendency of a player to be part of passing triangles or localized groups (i.e., whether their connections form closed loops).
These are metrics that player-based and focus on how a player is in possession and out of possession. This distinction is important to us, to have an idea where to look later as we approach out of possession metrics.
These metrics are calculated in Python by analysis — using code- the relations between players in terms of passing and their average positions.
Next to player-level data, there are so data metrics that are team-based. These are the following I’ve managed to calculate:
Network density: Measures the overall connectivity of the team, defined as the ratio of actual passes (edges) to the maximum possible connections.
Network reciprocity: Proportion of passes that are reciprocated (player A passes to B, and B passes back to A).
Network Assortativity: Measures if high-degree players tend to pass to other high-degree players
Analysis I: Adjust passing networks with player-receiving values
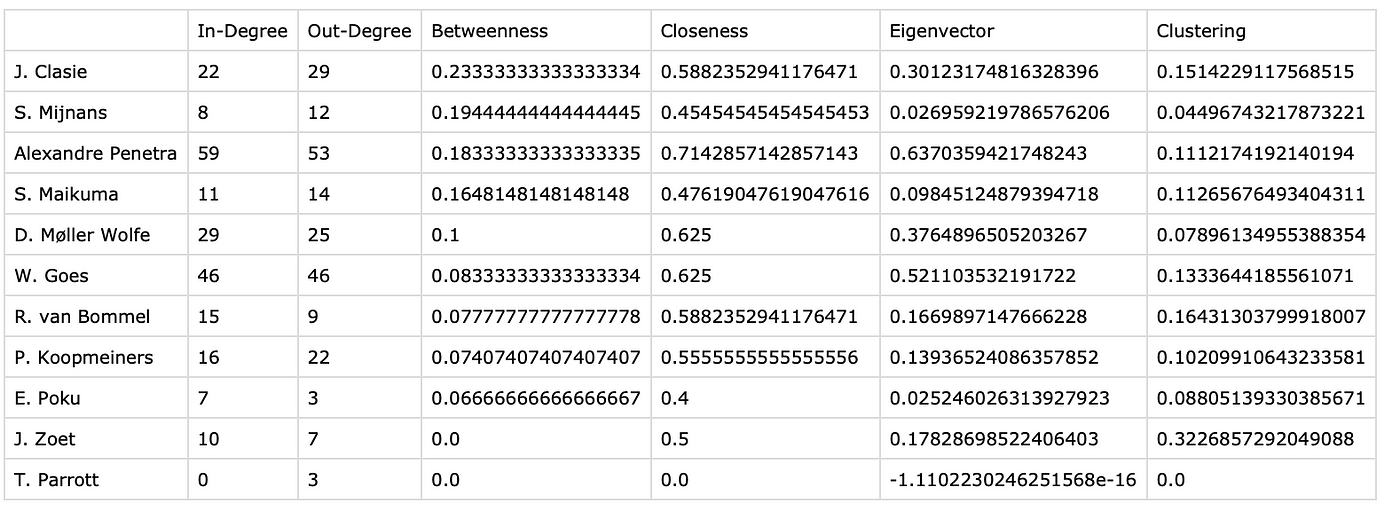
We calculate the newly developed metrics and form them into a CSV/Excel file, whatever your preference is for analysis. It will look like this:
As you can see we have the distinction between passing and receiving in general. We want to focus on betweenness, which is important: A player with high betweenness centrality is a key link in the team, acting as a bridge between other players. This highlights their importance in maintaining the flow of play.
If we look at this specific game, we can see that Clasie is the player who is most important as the key link in the team, followed by Mijnans and Penetra. It’s not weird that the two midfielders are linked so importantly, but the central defenders getting the ball so often, means something for the security and risk-averse style of the play.
We can also use any of the other metrics to illustrate how a player is doing, but you get my drift: value is there to be added.
Of course, this is on a player level, how does this translate to team-level for this specific game?
On their own these metrics mean nothing, they have to be in relation to other games that AZ has played or have to be benchmarked against the whole league. They however do tell us something about how close the average positions of the players are in relation to each other: a high density means that the team has good ball circulation and most players are connected through passes. A low density may indicate a more direct, counterattacking style with fewer connections. And, that’s something that’s valuable in the bigger picture.
Analysis II: Player comparisons
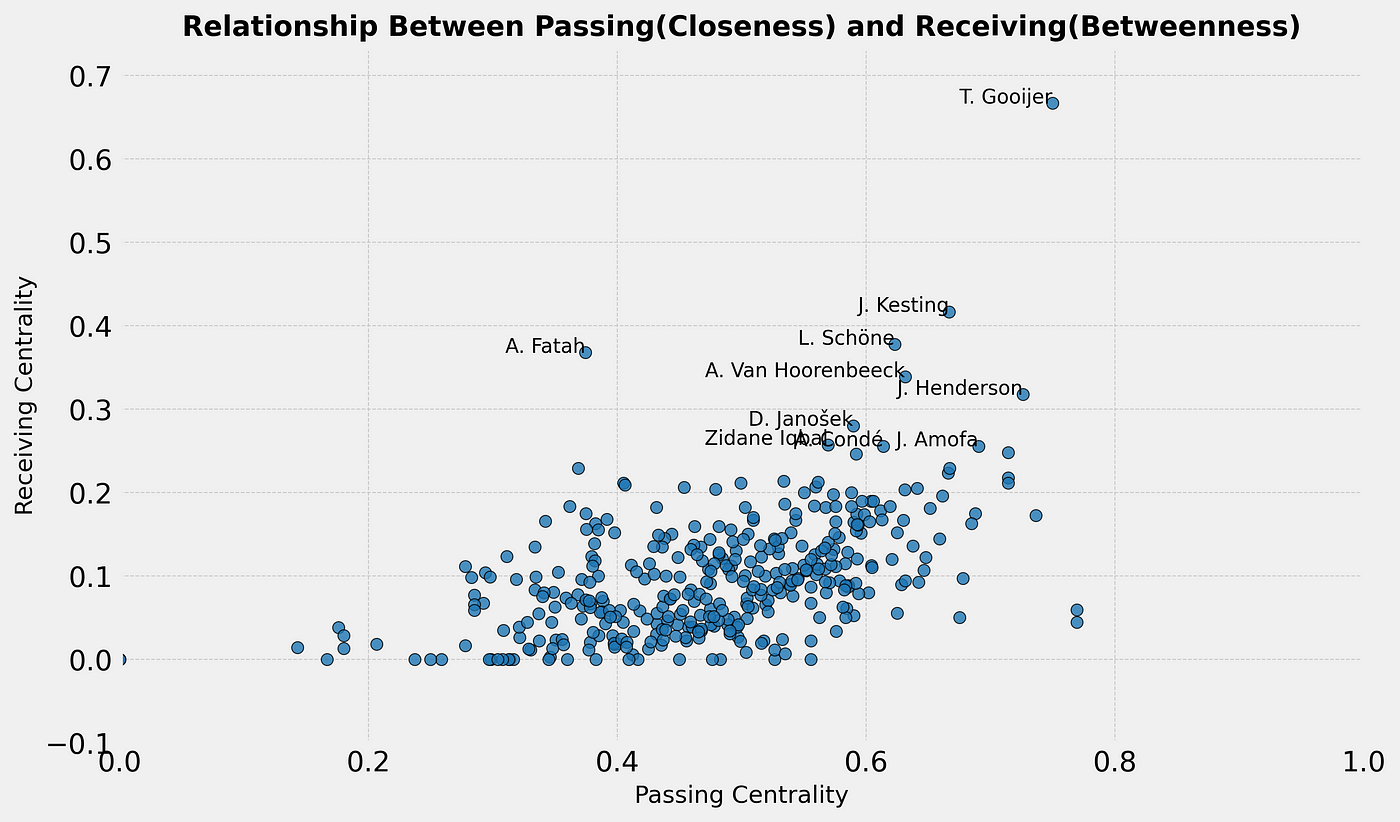
We also want to see what the relation is between passing and receiving for the key players. We will look at Betweenness and Closeness, which give value if you are closest to receive or pass the ball to the closest: are these key players equally good in both or do you find different outcomes?
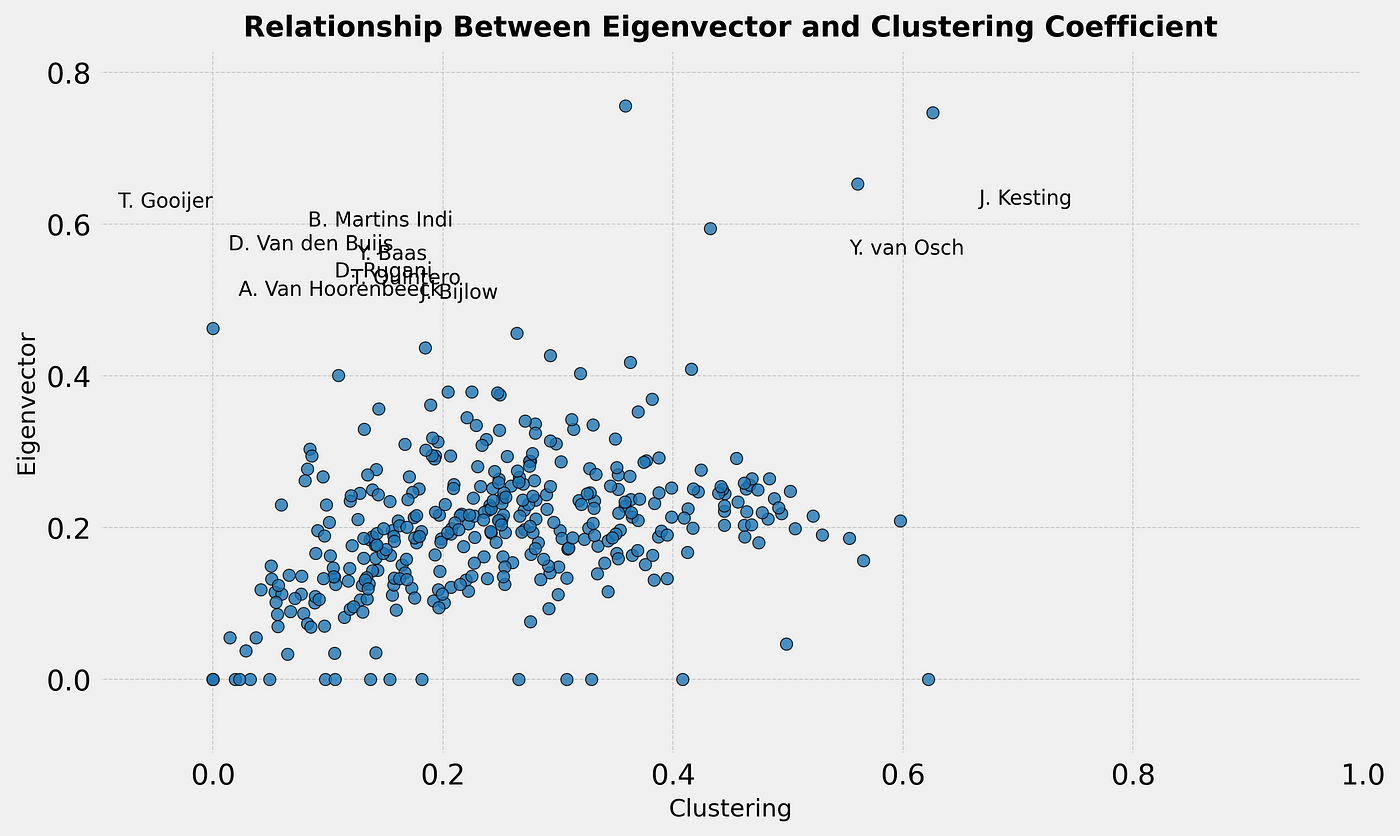
If we look at the scatterplot above, we don’t see many outliers and we only see the top 10 players. However, an interesting conclusions we can draw from this is that players are more likely to score higher on passing the ball to the closest teammate, than they are to receive it from the closest teammate. Tristan Gooijer (PEC Zwolle) being the exception.
If you look one step further and compare Eigenvector centrality to Clustering Coefficient, we get some different insights. Eigenvector focuses on a key player also linking with other key players, while clustering coefficient focuses on how well a player is connected in passing triangles.
As you can see in the scatterplot above, the relations are quite different here. The most important players are more likely to be included in the passing triangles, confirming that key players will always look for each other.
Methodology Part II: Creating OBIS
Now, I want to take the next step and the last step. We want to see how we can create an off-ball value score from passing networks. We can do that as follows. We will filter the new metrics and choose those we think we will help in calculating that metric:
In-degree centrality: A player with high in-degree centrality is frequently targeted by teammates and serves as a passing hub or focal point.
Betweenness: A player with high betweenness centrality is a key link in the team, acting as a bridge between other players. This highlights their importance in maintaining the flow of play.
Eigenvector: A player with high eigenvector centrality is well-connected to other influential players. They amplify their team’s passing efficiency by linking with key teammates.
To make the score, I have a formula:
We have the three metrics as described above and they all have a weight. Some metrics are more important for the score than others. In this instance, In-degree has a weight of 0.5, Betweenness a weight of 0.3 and Eigenvector a weight of 0.2.
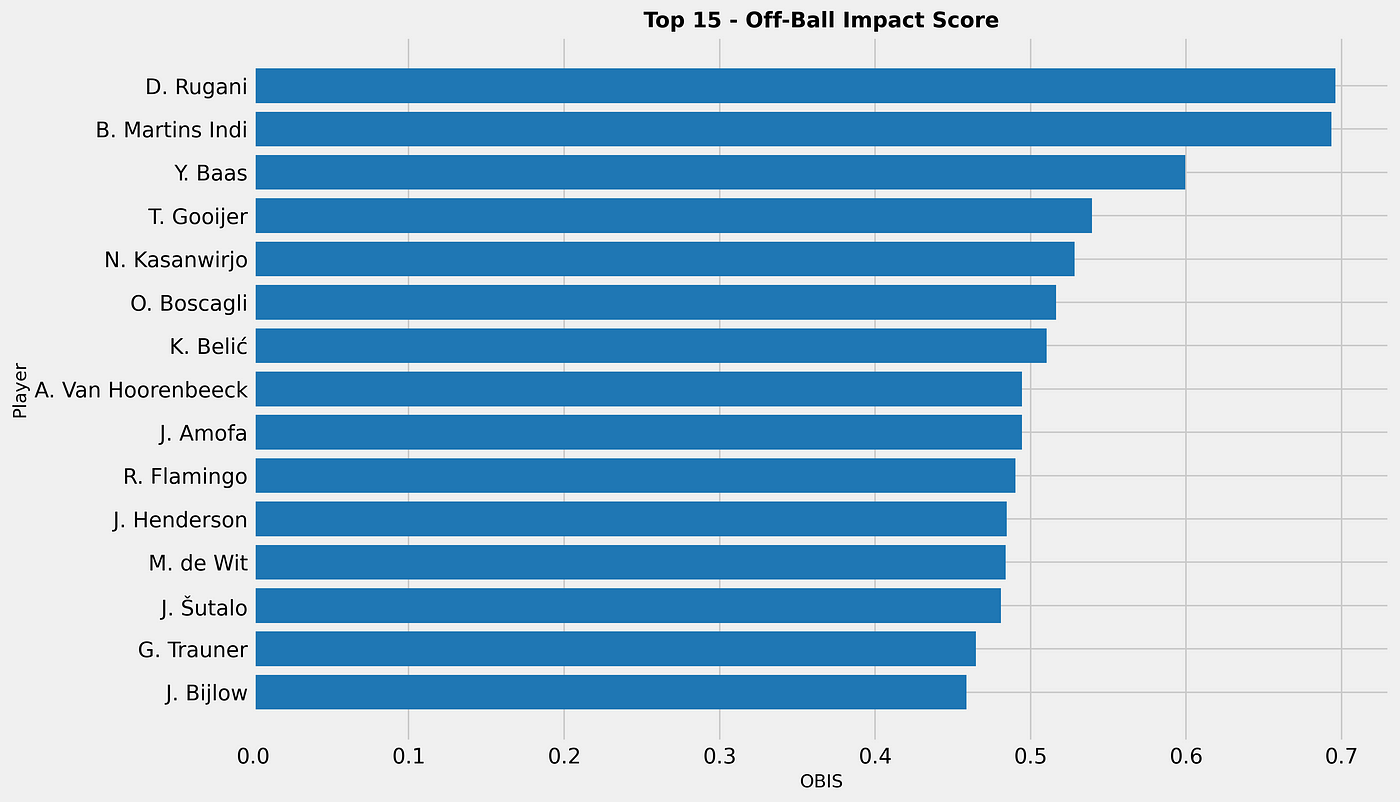
Analysis III: Off-Ball Impact Score (OBIS)
If we look at the total season so far and the OBIS, we can see that these 15 players score highest in this metric. We want to convert this into a score from 0–100 and if we do that, we get the following scores for the top 25:
Obviously,, this is a season score and we can also look at this from a individual level. And, with that I mean the match level. How do we add value to the passing network with using OBIS.
We are looking at a different game and this time it is the SC Heerenveen — PSV game that ended 1–0 for the hosts. We will focus on PSV.
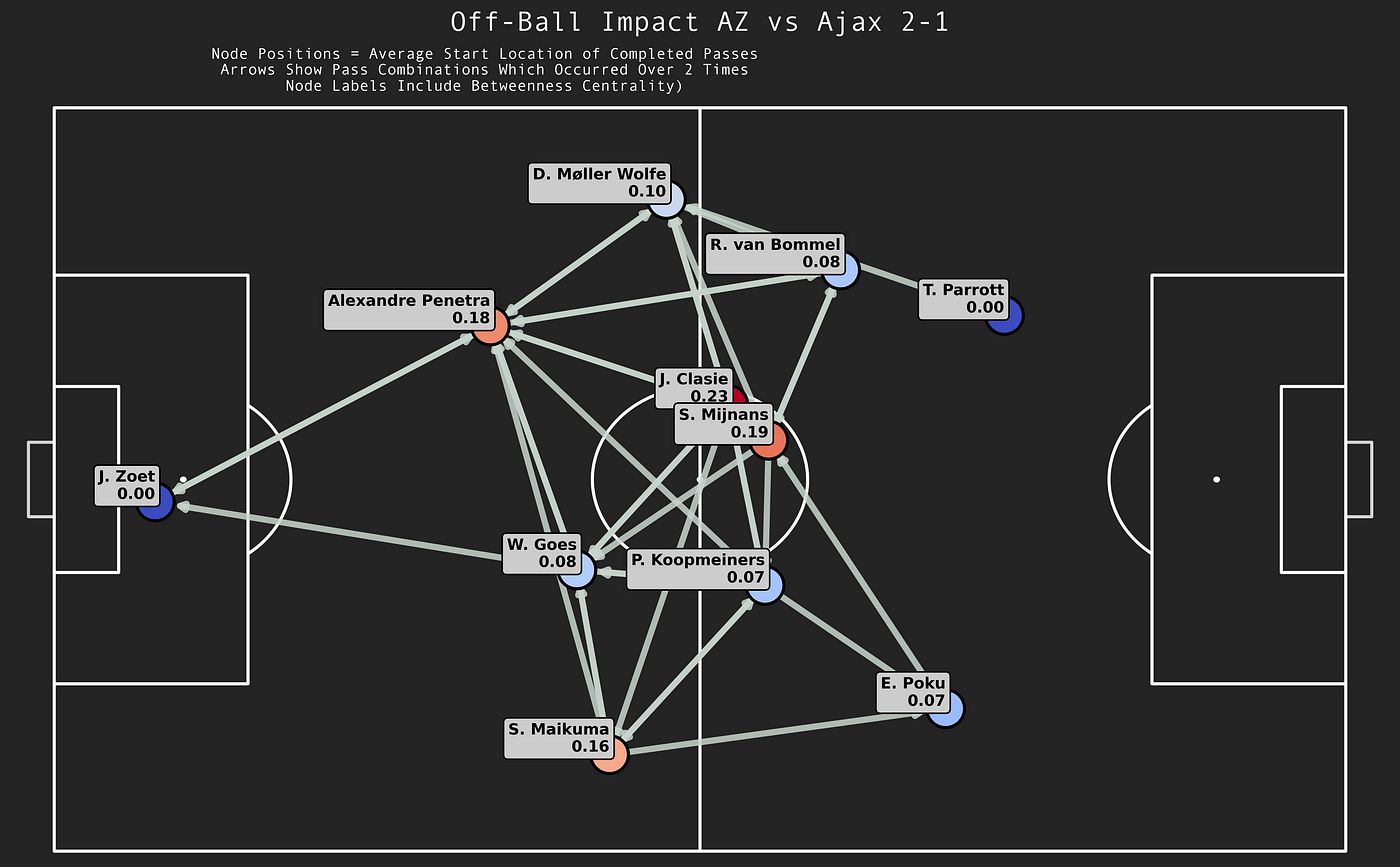
In the pitch above you can see the passing network of PSV in their game against Heerenveen, but with the nodes coloured based on the OBIS they had in this particular game. In other words, which player had the most impact in not passing, but receiving the ball.
Final thoughts
OBIS is a promising metric for evaluating player performance by combining key network-based metrics like in-degree, betweenness, and eigenvector centrality. By weighting these factors and normalizing them, OBIS provides an insightful measure of player influence on the field. However, further refinement could enhance its accuracy and adaptability. Incorporating additional metrics (pass completion, defensive actions) and considering context-dependent factors (game state, opponent strength) would improve OBIS’s ability to reflect a player’s true impact. Additionally, using machine learning to fine-tune weightings and integrate spatial data could offer a more nuanced, dynamic representation of player performance.
Expected goals. We have been discussing its use for years in the data analytics space, not only in football of course, but also in spaces like Ice Hockey. We look at the likelihood or probability of a shot/chance being converted into a goal by looking at different variables. One of these variables is the angle, which I want to talk about today.
One of the variables is the angle of the shot and we need to have a look at that because it also tells us something about the player’s ability to shoot from different angles and make something meaningful out of it.
Why this article?
That’s always a good question. I think it’s important to stress that everything I write here is because I think it’s interesting and has some merit in the public analytics space. However, it doesn’t need to be something that will be used when working for a professional club, so I think that’s always an important distinction to make.
I want to have a look at the correlation between expected goals (xG) and shooting angles: how much does it influence xG and can we find players that score from tighter angles more than others?
Data
The data has been collected on November 23rd, 2024. The data is from Opta and is raw event data, which I later ran through my expected goals model to get the metrics I need:
Players
Teams
xG
Angle
Opposition
I will focus the data on the Eredivisie 2024–2025, because that’s the league I watch the most and are most familiar with.
Methodology
To calculate the angle of a shot in football, we determine the angular range a player has to score into the goal, considering the shooter’s position and the goalposts. This angular range, referred to as the “shot angle,” is calculated geometrically using trigonometric principles.
The shot angle (θ) is defined as:
where:
goal_width is the horizontal width of the goal (typically 7.32 meters in standard football pitches),
distance_to_goalis the Euclidean distance between the shooter and the centre of the goal.
If the shooter is positioned off-centre, the angle is calculated between the shooter’s position and the goalposts:
With this calculation, we can see what the angle is for every shot taken in our database after I’ve run it through my expected goals model. We then have all the information we need to make a visualisation of the shot and the angles.
In the image above you can see the angle of the shots highlighted. The angle of the shots is obviously a number, but what does that look like in the visualisation of a shot map?
On the pitch above you can see an example of a shot with an angle of 22 degrees. It shows the distance and the shot location, which ultimately also leads (along with other variables) to an xG of 0,05.
In the pitch above you see a different example. The shot is closer to the goal and that also means the angle will be wider, ultimately giving a bigger chance of hitting the target and scoring a goal. This also means that the xG is significantly higher with 0,41.
Location and how wide an angle is, matters.
Analysis: players and good angle positioning
With this information, we can go further into the analysis. In this analysis we will use the width of the angle and measure that against the expected goals per player. To do that we will look at the average xG per shot and the average angle per shot.
If we look at the scatterplot above, we can see the top players in both metrics. This means that they have the highest xG per shot compared to their peers and have the highest width of shots when we look at the angles.
The idea is that players with higher width in terms of angle will be closer to goal and more centrally, thus improving the chances of scoring a goal. This means that the majority of their shots will be closer to gthe oal. Let’s test that with Brian Brobbey’s shot map in the Eredivisie so far.
As you can in Brobbey’s shot map (up to date until November, 23rd 2024) Most of his shots come from the centre. Within the six-yard box or within the penalty area. Brobbey is more likely to generate a higher amount of xG due to this angle being wide due to his shot location.
Final thoughts
The correlation between xG and shooting angles is quite evident. A higher/wider angle often means a higher xG, which means there’s a higher chance of scoring.
While shooting angle isn’t the sole determinant of xG, it is a critical factor. Combining angle, distance, and situational context provides a complete understanding of a player’s goal-scoring efficiency.
Data helps make decisions in football, but most of the data out there helps analyse teams and players in post-match analysis. This means that we look after the events and determine performances. This gives us a scope of how players have done in a particular time period or how a team has faired against other teams.
I promise you that at some point, I will stop creating new metrics or presenting you with player scores. But I just love them. The reason for that is that event data allows us to play around and make our own metrics. You can tailor the data to the needs you need, but you have to stay vigilant: it’s incredibly prejudiced and subjective. Data also has to deal with narratives and that’s something I hope to give you all if you find these articles interesting to read.
Sometimes I wonder what I really love to write about. And, in all honesty, I don’t usually write about the stuff that truly fascinates me. My mind goes to the audience — you — to discuss what I think will do well for my audience. That’s a good way of approaching the market. Attacking numbers or players always do well, but I think that the attacking pieces are plenty and those of defensive data aren’t. So, that’s why I want to look at data that truly fascinates me and I enjoy defensive data.
For this article, I’m going to have a look at long passes or long balls. The aim is to create a metric via a score that judges not the length of the passes or the end location, but rather looks at the starting location. I have always been fascinated with central defenders who dribble up the pitch or defensive midfielders who distribute from deep, so with this, we can measure how they contribute to their team’s attack.
Data
The data I’m going to use for this specific research is event data from Opta. This was collected from the 2024–2025 season and focuses on the Austrian Bundesliga. I won’t make any distinction for position here, because in terms of average position it will most likely be central defenders dribbling in, defensive midfielders dropping or fullbacks/wingbacks from the half spaces.
Event data will be manipulated so it can be used as match data. This means that will go from XY data to metrics, which is more usable in this kind of visualisation like tables and scatterplots.
Methodology
The aim is to go from event data to results that are totals or per 90 metrics. I have previously made metrics via Opta event data and using standard qualifiers to determine long passes. Which will be helpful.
So what’s a long pass? That’s the first question we have to ask ourselves in this regard. We can determine a long pass from the total passes when:
A pass is a ground pass over 45 meter
A pass is a high pass over 25 meter
From that we get a total number of passes based on those qualifiers. But what we are going to do next is to filter those passes. I can do that in the first step already, but since I already have that information I will do it after. I will determine the start location area to make sure I’m getting the right ones.
I will calculate that through Python where I put the event data through a set of calculations. Without limitations we get this:
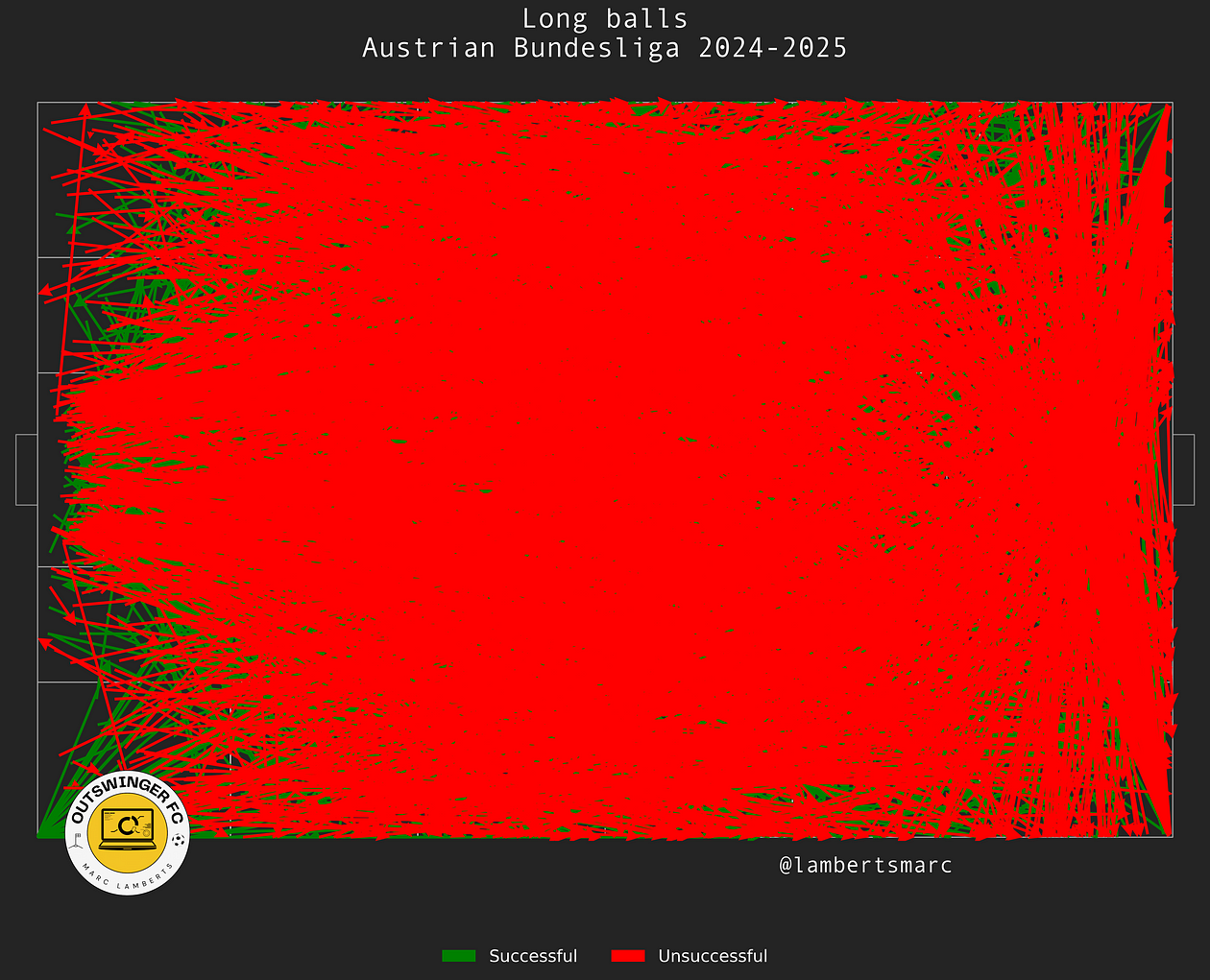
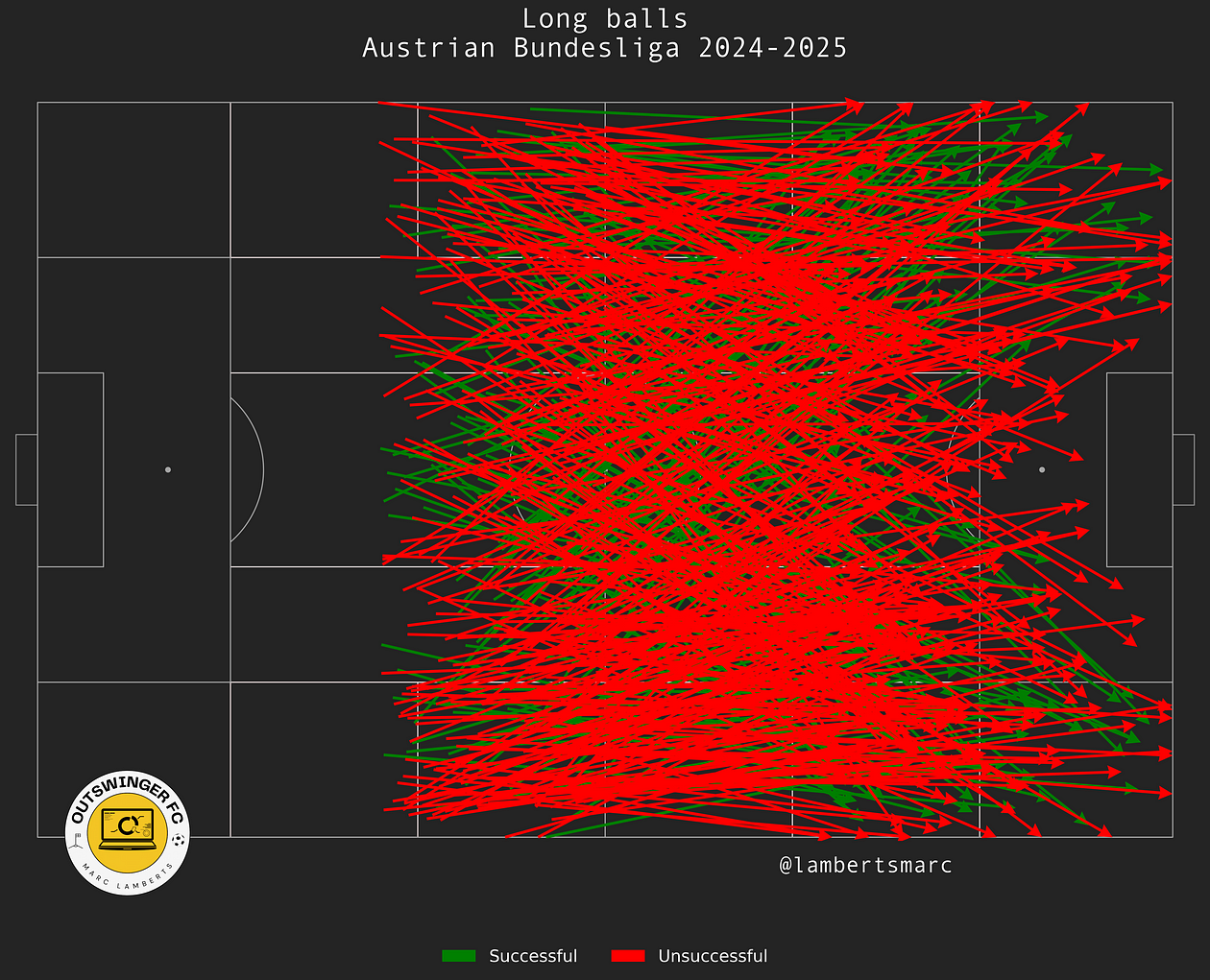
Of course this is impossible to distinguish and doesn’t give a lot of meaning to what we are trying to achieve. We want to look at start locations that are in the middle third. From the start location in the middle third, we can see the total long passes in the Austrian Bundesliga so far.
In the image above we can clearly see all passes that fit the begin location, but what we also see is that passes have that particular start location, but not the progressive end location. Many of the passes go backwards and that’s not what we want, so we have to change that.
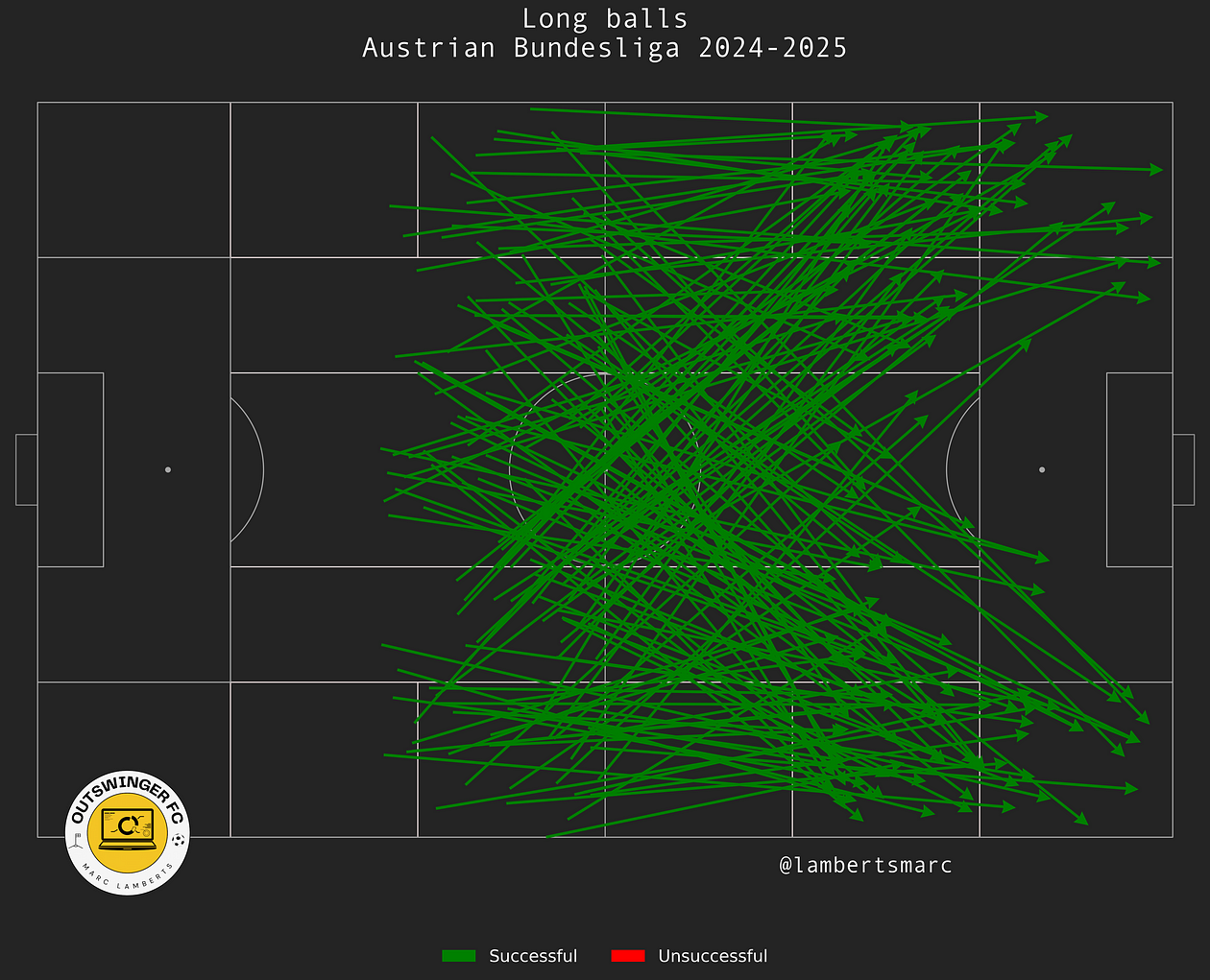
In the image above you can see the corrected version. Now all the passes go forward and beyond the half of the pitch. It already gives us a better idea of progressive long passes, but not quite yet. We still have to filter out unsuccessful passes.
Now we have all the passes that we need to make the metric and create the score to see which players are doing the best in this metric.
Progressive Long Pass Score
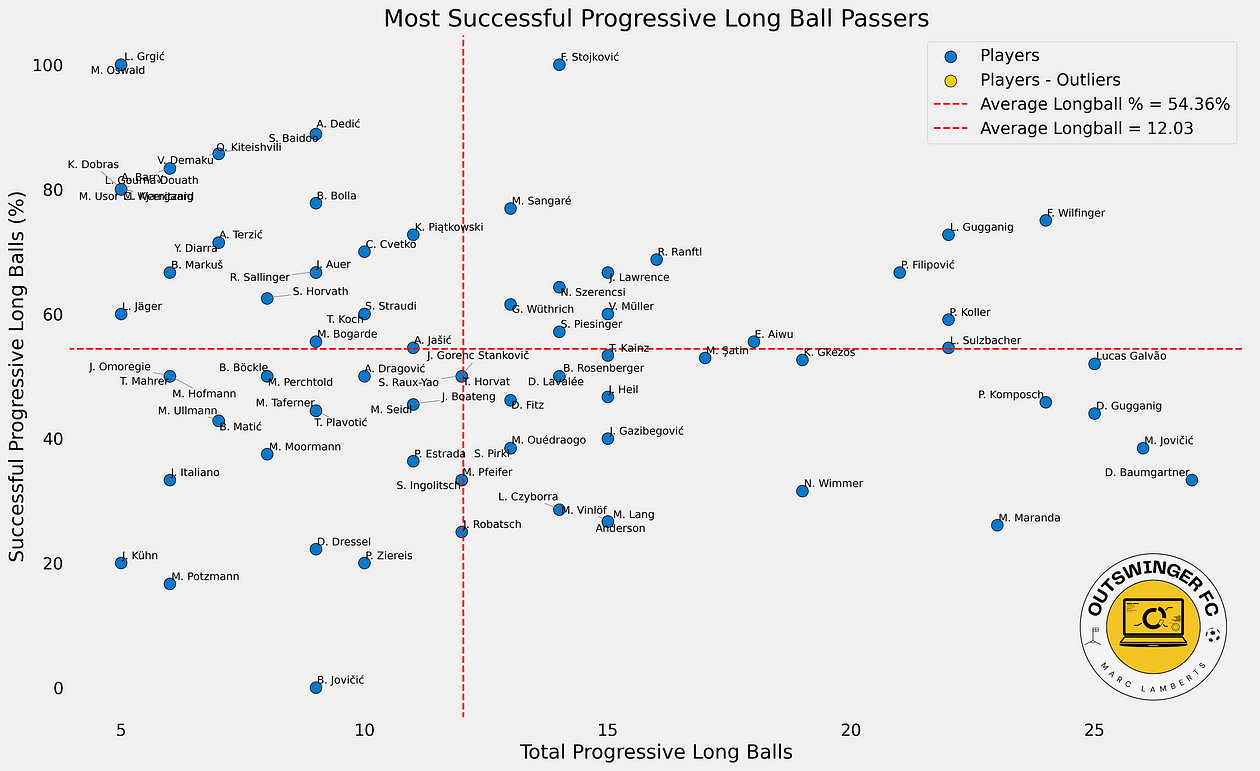
So first we have a look at progressive long passes and the success rate of those passes. This gives us an idea of how successful players are when conducting this kind of pass.
In this scatterplot we see the relation the total of progressive long balls and their successrate. I have filtered for players that 5 or more long balls to not skew the data when we are looking at metrics and scores. The next step is to convert this to a score.
We will look at the metrics and give new weights. The successrate is leading, but the weights of the total progressive long balls plays a part too. The success rate will become more important in the score when the volume of long balls is higher.
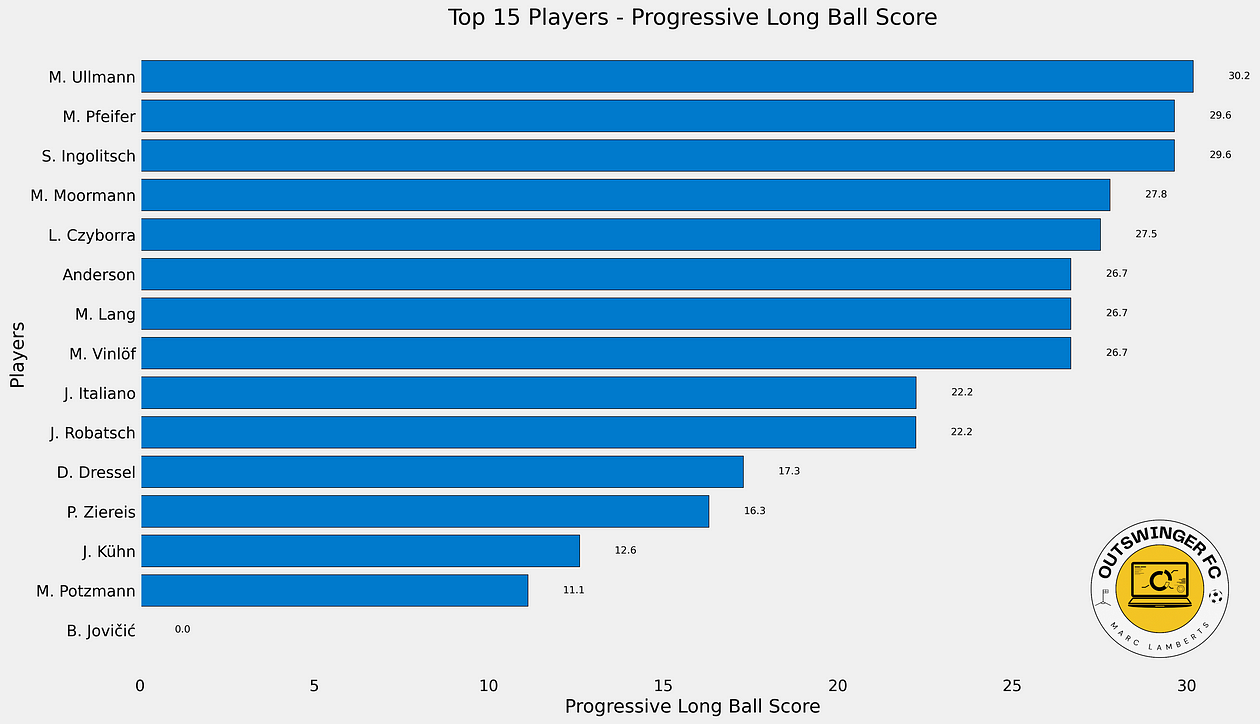
When we have created the code, we see the following score and rank for the Austrian Bundesliga in terms of Progressive Long Ball Score.
If you want to know more about the Python code, you can subscribe to my Patreon here:
Set piece analysis is growing within club football and I very much welcome this development. When looking at set pieces you can actually divide them into 4 separate categories: corners, free kicks, throw-ins and penalty kicks. I think all categories have their own way of approaching them, but I want to focus today on throw-ins.
Throw-ins are often approached the same way as corners and free kicks are, but that’s not the way of properly analysing in my opinion. You have to work with different metrics and dynamics, and that’s why I’m relatively new to working these things out. What I can do, and will do, is look at how we can use data to see whether teams have benefited from throw-ins.
Data
To make this analysis possible we need data to generate actionable metrics. We need event data from leagues we are looking at. For this I collected event data from the Dutch Eredivisie (NL1) and the Belgian First Division A (BEL1) for the 2024/2025 season. The data was collected on September 1st, 2024.
We will look at the teams specifically and not players, so we don’t need to filter for minutes played or certain positions, which makes this part of the research less intense.
Methodology
The idea is to work with event data and use Python as a programming language to convert all those XY data into metrics we can work with. We will convert passes from throw-ins and also look at how these throw-ins are successful but also lead to shots from that particular throw-in.
In the image above, you can see all throw-ins made in the Eredivisie in the attacking half of the pitch. It doesn’t show a lot, but it shows the successful and unsuccessful throw-ins, which can give us insights into directions and progression.
The next step is to find successful throw-ins that lead to shots so we can measure their effect/impact. This means we will look at the next few actions following a throw-in to determine that a shot comes from a throw-in rather than from another action on the pitch.
Metrics
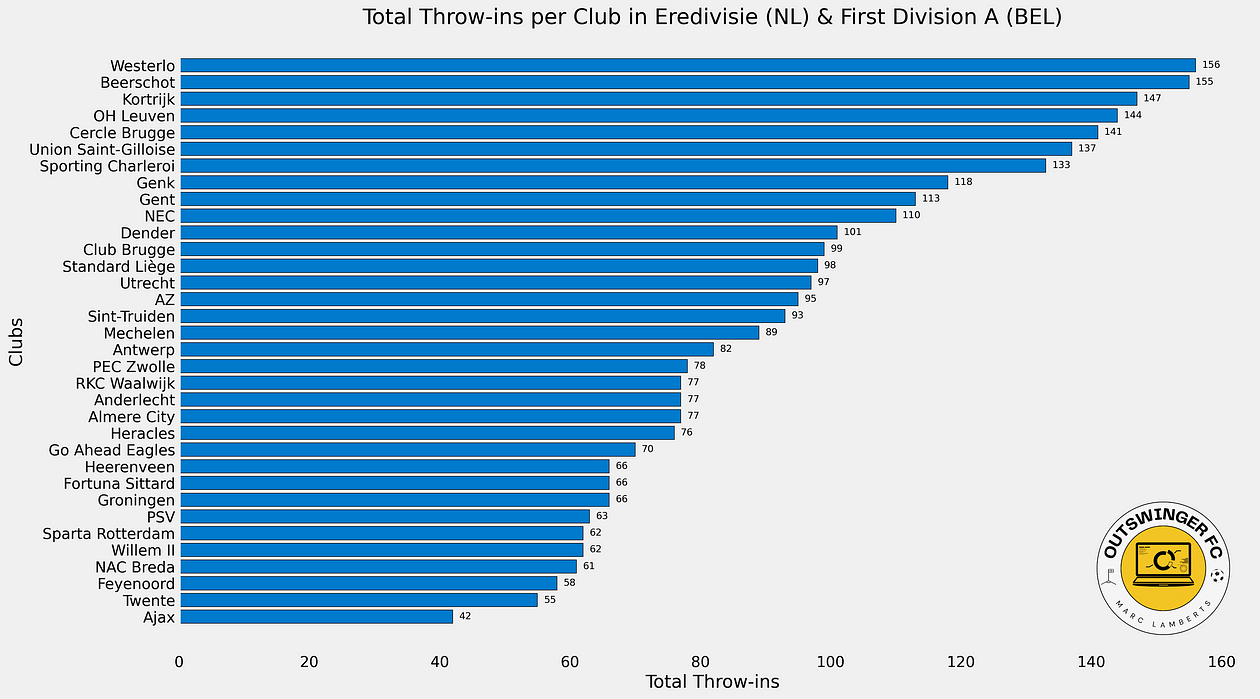
Of course, I have visualised the throw-ins as passes but essence is that we can calculate the number of throw-ins per team for those two leagues. This gives a clear image of which teams do throw-in the most — or get the opportunity to throw in the most.
We now see a list of all teams in the top tier in Belgium and the Netherlands based on quantity. This will give us insight into how often teams have a throw-in.
The next step will be to make the conversion from throw-ins to throw-ins leading to shots, which will be the basis for analysis.
Analysis
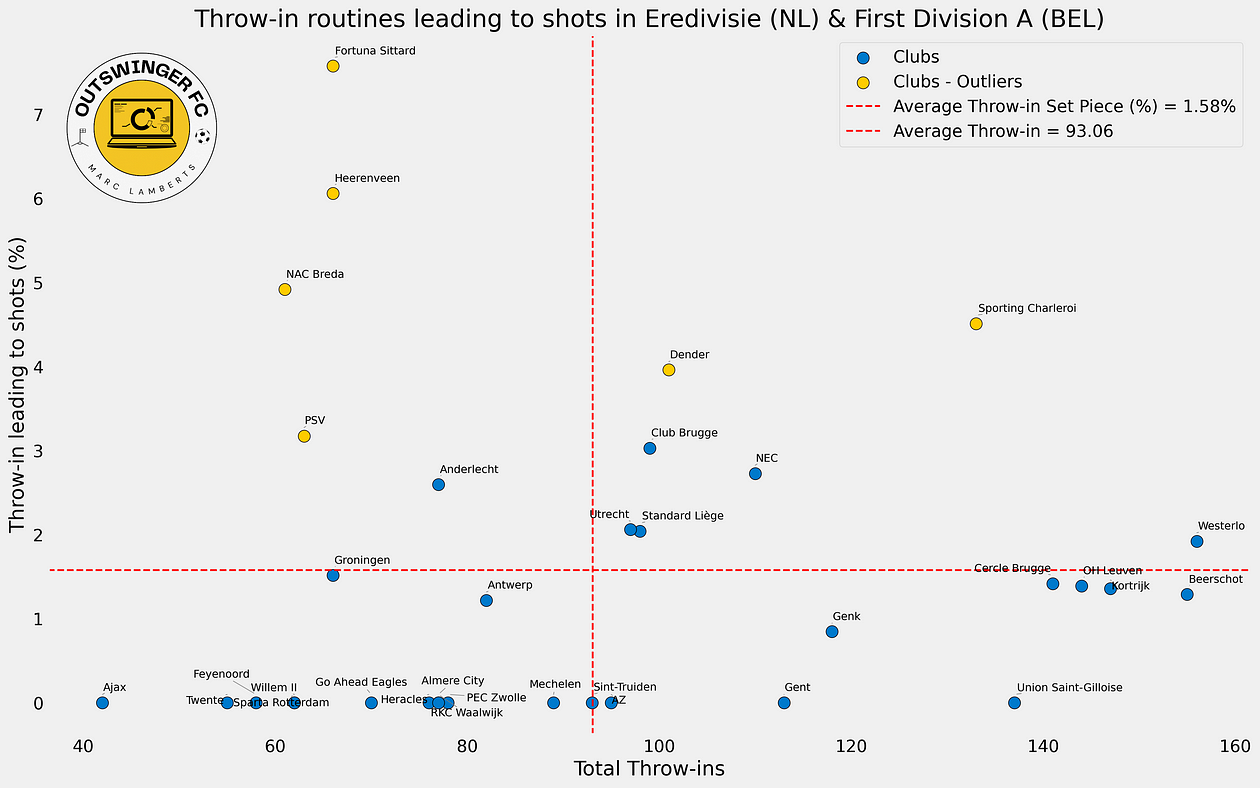
The analysis is focused on having an idea whether a team makes the most of their throw-ins. In other words, what percentage of throw-ins will lead to a shot?
In the scatterplot above you can see a few interesting things. First of all it shows the relation between throw-ins and throw-ins leading to shots and you can see the conversion in percentages. The percentages are all under the 10%, and that’s something we really need to have a look at.
The average number of throw-ins is 93,06 and the average percentage of throw-ins leading to shots is 1,58%. In this case, we are looking for the quality and mostly looking for the clubs with the highest percentage.
So the left upper quartile is most important for that part of the analysis as it shows the clubs with the least number of throw-ins, but also with the highest percentage: their emphasis is based on getting shots from throw-ins. Now the right upper is also important, but the relation is different there with the total number of throw-ins.
I’ve also colour-coded outliers for both metrics, but most important is that they are outliers for the percentage of throw-ins leading to shots. This shows us that these clubs/teams are performing many deviations from the mean and these are the teams to have a closer look at.
I’ve not dabbled a lot with throw-in data, but this is a very good way of making the first step into it. From here on we can find teams that are most prolific from their throw-ins and see from video if they are doing interesting things. Of course there is much to improve and to build on, but for now this gives me a good framework to use data in this part of set piece analysis.
In the new season 2024–2025 I want to try something new. I’ve been dabbling a lot in innovation (think of creating new metrics) and using analysis with existing data, but that’s not enough for me. It’s quite standard and I want to give more insight to what happens when you tailor your metrics whilst working for a club and make it actionable.
That’s the major issue with online content, it’s mostly present because it speaks to an audience — and I’m definitely part of that issue. I write not for myself only, but also in part because I know my audience would like the result of what I’m researching. I don’t think I can change that, but I can show you a little more about what the design of a metric means in the light of actual analysis within a club or organisation.
In this first installment I will focus on header ability. I want to create a metric that gives a rating to individual heading ability. With that rating that will change after each matchday, I can show probability of a player winning a duel. The actionable part here is that we can use that particular info when we are training and preparing for set pieces in the next game. IF we employ 3v3 runners vs blockers, we want the best winning probability in the air to maximise our delivery.
Why do we need a metric that measures ability
Football is a lot about tactics and avoiding trouble, but there are a lot of areas of the game where we have to focus on duels. It is a contact sport so we need to be aware that this will always be part of the game. To win critical battles on the pitch you need to make sure you can win little parts of it and that’s where aerial duels come into place. If you want to control the central areas of the pitch, you will have to deal with long goal kicks for example. This means there will be a battleground in those zones, so you need a strong force in the air.
I was trying to come up with ideas to look at aerial duels and came across this article about a metric designed by Statsbomb. Because, of course I was too late to actual invent a new idea.
It’s a very interesting concept and I wanted to recreate it, but also make it different. I want to look at aerial duels per 90, aerial duels won in % and height, but I also want to look further. I want to see if more metrics can be incorporated or see if different weights can be used for specific metrics. Recreating metrics is a great exercise for data analysis and data engineers, but more often than not you realise you are not completely satisfied with things that have been done before. That’s why I wanted to do it a bit different: I want to evaluate heading ability for individuals, with a link to probability and come with Power Ranking for Individual Set Piece Strength based on heading ability.
What do I need to make this happen?
There are several things I need to make this happen. First of all I need the full data of full season in a specific league or number of leagues. For this particular research, I’ve chosen the Eredivisie 2023–2024. This data can come from StatsBomb, Wyscout, Opta or any other data platform you are using. I’m using Wyscout data and specifically look at four specific metrics:
Height: the influence of height on the aerial duels is not to be underestimated. There is a correlation and we will see later what that looks like.
Aerial duels per 90: the number of aerial duels means something because it indicates how often you come in these duels and therefore your rating can constantly change.
Aerial duels won in %: yes the number of duels is very important, but the win percentage tells us everything about quality. And, that’s where the real advantage will come from.
All the players will have played at least 900 minutes and will be excluded when they are goalkeepers. Their aerial duels are from a completely different calibre and need to be addressed in another research.
Methodology
There isn’t one specific methodology, because I want to make different things. I will be making a rating (and a score based on that rating), a probability and a power ranking based on that.
For the rating I will make sure there is a weighting for the metrics used. I will give a weight of 0,5 to the height, a weight of 1 to the numbers of duels and a weight of 1,5 to the win percentage of those duels.
After that I will use the glicko method to calculate the rating. I can also use ELO, but there is a reason I don’t. Glicko2 is more accurate in terms of predicting match outcomes or win probability and that’s essential for my process in doing this all.
Lastly, I will be making a power ranking and for all of these things I need to make a lot of calculations. These calculations will be made using Python.
Individual Header Rating (IHR)
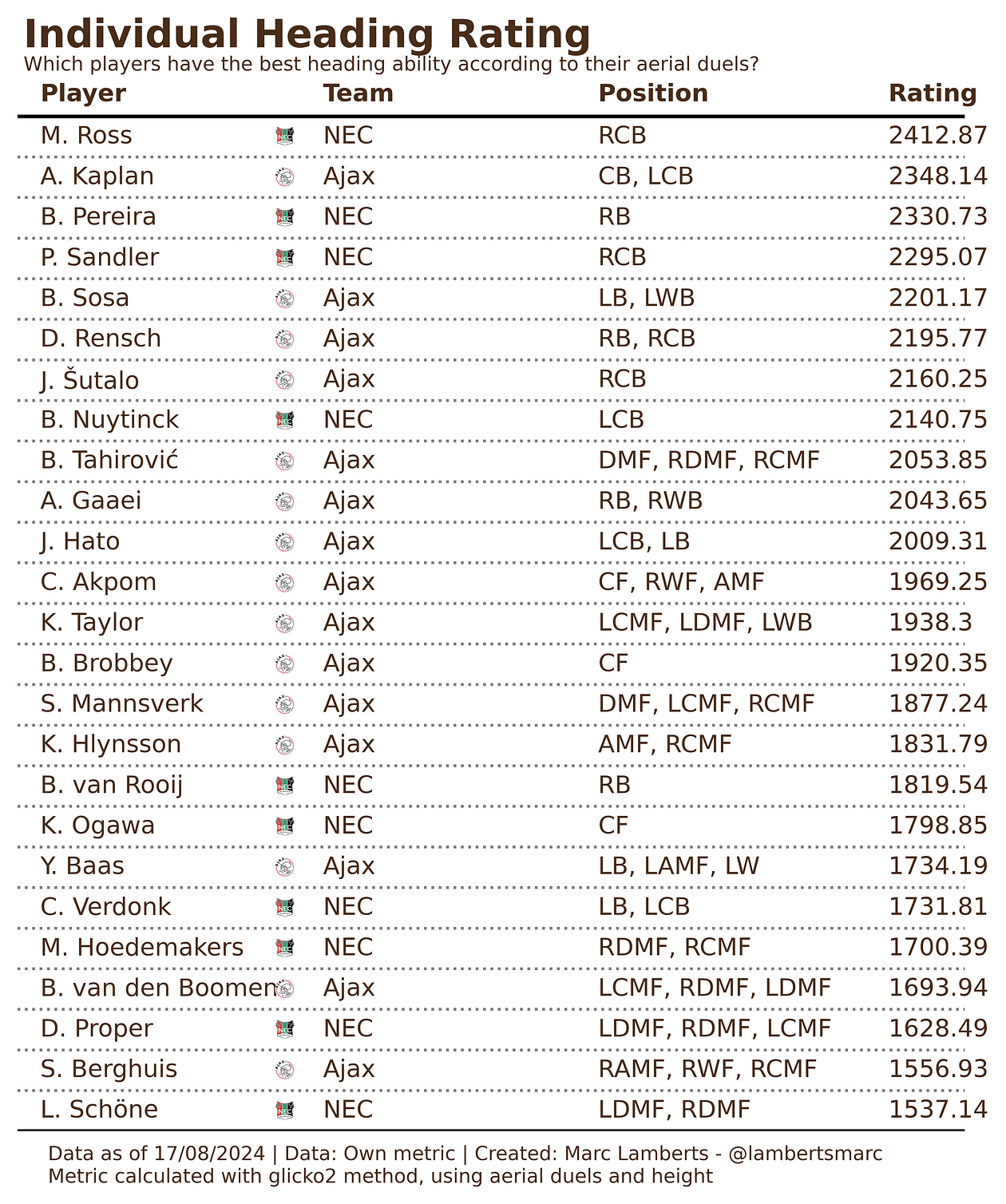
By using glicko calculations I can calculate a rating based on the weights I’ve described above. By doing so I get a list of the players who score highest. For this example, I will take the top 15 performers according to this rating.
When we look at the table above we see the top 25 players and their rating. The rating is based on glicko2 method, which can be compared to an ELO rating, but again, the calculations are quite different.
When we want to look at an easier comparison for players instead of a ranking, we will convert them into a score from 0–100.
As you can see in the table above we have managed to show the top 10 players and their corresponding score. In this case we can then state that these players are most likely to win their aerial duels against other opposition.
Win Probability
We we will go into changing ratings and scores in a bit, but before we can get there, we need to talk about win probability. If we think a player is going to match up with a player during the length of the game, we can look at how likely it is that the a player will win.
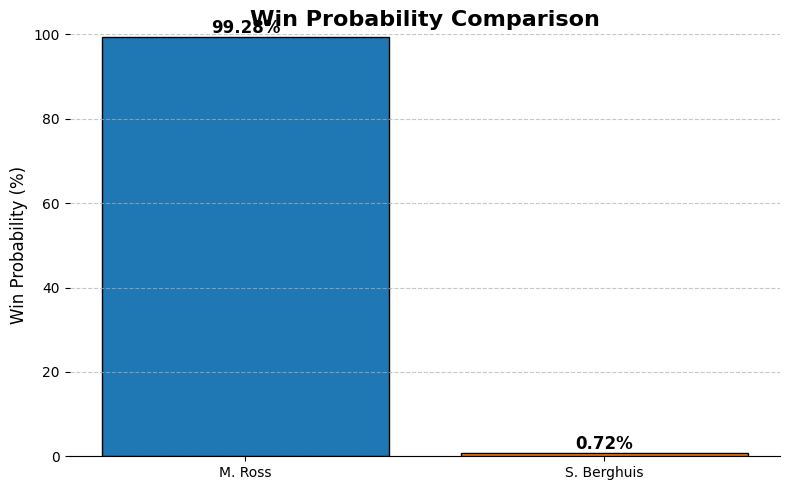
I want to look at two players that might come across each other in a match. In the attacking side I’m going for Luuk de Jong (81,24) who is a threat in the air for PSV. He will play against Lutsharel Geertruida (83,85) of Feyenoord, who might come across to defend him and is very strong in the air too.
Using just the score, we can conclude that the win probability for Geertruida is 54,70% against 45,30% for De Jong. That matching up can be favorable for Feyenoord and PSV might want to think about a different match up. More on that later.
New ratings
So from that probability we move on to the new ratings and effectively making a power ranking. We will continue with these two players and look at the effect of the probability being the actual result.
Geertruida had the win probability and also won the aerial duels (absolute numbers in the majority) and that means his new rating is 2211,73 from 2210,45. De Jong lost and went from 2177,66 to 2176,38. In the grand scheme of things their ratings did change, but their place on the ranking did not. Geertruida stayed at place 33 while De Jong also stayed at place 40.
The place might stay the same, but over a whole season, things can fluctuate and become different. That’s how we can have an individual power ranking based on the Individual Header Rating.
Actionable analysis
Let’s pick Ajax for this analysis. They need to play against NEC in their next game and they need to know how well their own players are doing in the air and how NEC is doing as a whole.
In team performances for this metric, Ajax scores 7th and NEC scores 16th. From this you can conclude that Ajax is better in the air as a team that NEC is. That would lead to soft conclusion that this would also work to Ajax’s benefit in defending set pieces and attacking set pieces.
Now, let’s take a closer look at the individual players.
In the top 5, NEC has 3 defenders and Ajax 2. This means that in general we can see that NEC is stronger in the air with defending than Ajax. Ajax has more players overall who do well in the air in defence, but also in midfield and attack, while NEC isn’t that great in attack in comparison.
Suggestions could be that Ajax needs to focus more on the attacking and see solutions there, because the NEC defence is tough. Their attacking however isn’t as threatening, so the worry shouldn’t be there for Ajax.
The next step is how you match up in attacking set piece to make sure you create the upper hand. Let’s for a moment assume there are runners vs blockers of 2v2. If that would mean that Ross-Pereira would defend, Ajax would do well to get their highest rating players to go against them. That would lead to a higher probability.
Ross still has a higher winning probability, but it is much closer than when Ajax employ another player like Berghuis there;
If this were the case, according to our data, it would be very easy Ross to defend Berghuis. This would also lead to a difference in ratings after the game, but that’s purely for academic purposes.
Correlation between Height and Rating
Of course, there is a relation between the height of a player and the way it’s easier to win those duels in the air. You can see that in the scatterplot above. I don’t think it’s really weird to expect these results, but what can really help in this analysis is to look at outliers — they stand out and can lead to conclusions about someone’s ability to jump or go into an aerial duel. These outliers are marked in red.
Final thoughts
I had a lot of fun creating/writing this because this is something I use to determine my suggestions for set piece positioning to teams. Of course, data is just a part of the story and should always be backed with video to explain routines.
What I really wanted to show is that when you make metrics, there should be a practical use for it when you work in analysis with teams. It should add value to the process of the staff and the players. There are so many bugs, tweaks and turns I need to look at, but it’s an example of how making a metric can help in set piece analysis. Especially when most data metrics focus on delivery and shooting.
It’s not a surprise to most of people, but the Dutch Eredivisie is one of the most interesting leagues in Europe for different reasons. It’s a league where you can develop talent, but it’s also a league that often acts as a feeder league to the top 5 European leagues. This often constitutes the big players and the big clubs, but today I want to talk about something entirely different from that. Let’s talk about the bottom of the table.
I am an expert in the Dutch professional tiers — yes, I can say that at this point — and I have always been fascinated with how attackers perform. Not because of the number of goals, but because of how attackers perform in the lower brackets of the league. I love to explore how attackers with clubs at the bottom of the league perform and how they might continue that after relegation. The same is true for attackers in top teams in the second tier and how they will evolve — or not — in the Eredivisie after they are promoted.
In this research, I will attempt to look at the following question:
What happens to the shot ability and quality of attackers when they move leagues after promotion?
I can’t lie, I loved looking into this and finally bringing some different level of data analysis to two of my favourite leagues. It might be a bit far-fetched at times or not extremely relevant on the surface, but knowing the playing style of leagues and clubs will benefit the overall knowledge of the football culture in the Netherlands.
Table of contents
Data collection and sources
Methodology
Analysis — shot locations
Part of the total shooting
Percentile rank radars — attackers
Striking score 6.1 Eerste Divisie 6.2 Eredivisie
Final thoughts
1. Data collection and sources
The data used in this research comes from two data providers: Opta and Wyscout. Two different data approaches will be included in the research and the analysis:
Raw event data which we will use for the raw plotting data, creating new metrics, input for our xG model and much more.
Match level data is data that has been collected and provided into metrics by Opta themselves.
Match level data from Wyscout
With the data, we can do exactly what we need for the research. There will be an expected goals module that will give us xG values, but that’s all based on Opta data and will be explained more in the methodology part of this research.
The data was collected on Friday 12th of July 2024 and consists of the event data from Opta from the 2023–2024 Eredivisie season. The match level data comes from Wyscout, as we don’t have Opta coverage for the Eerste Divisie _ i know, it’s sad.
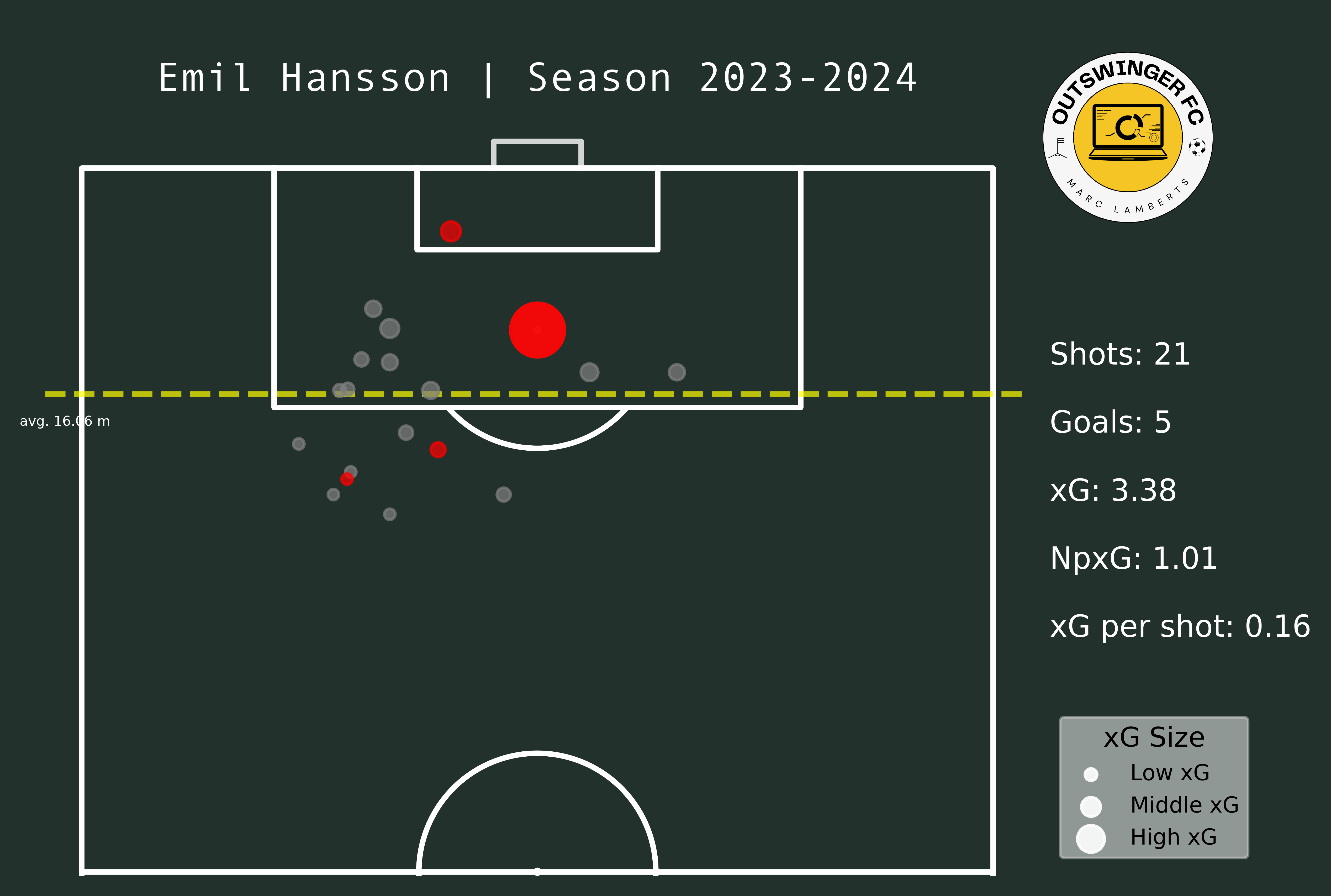
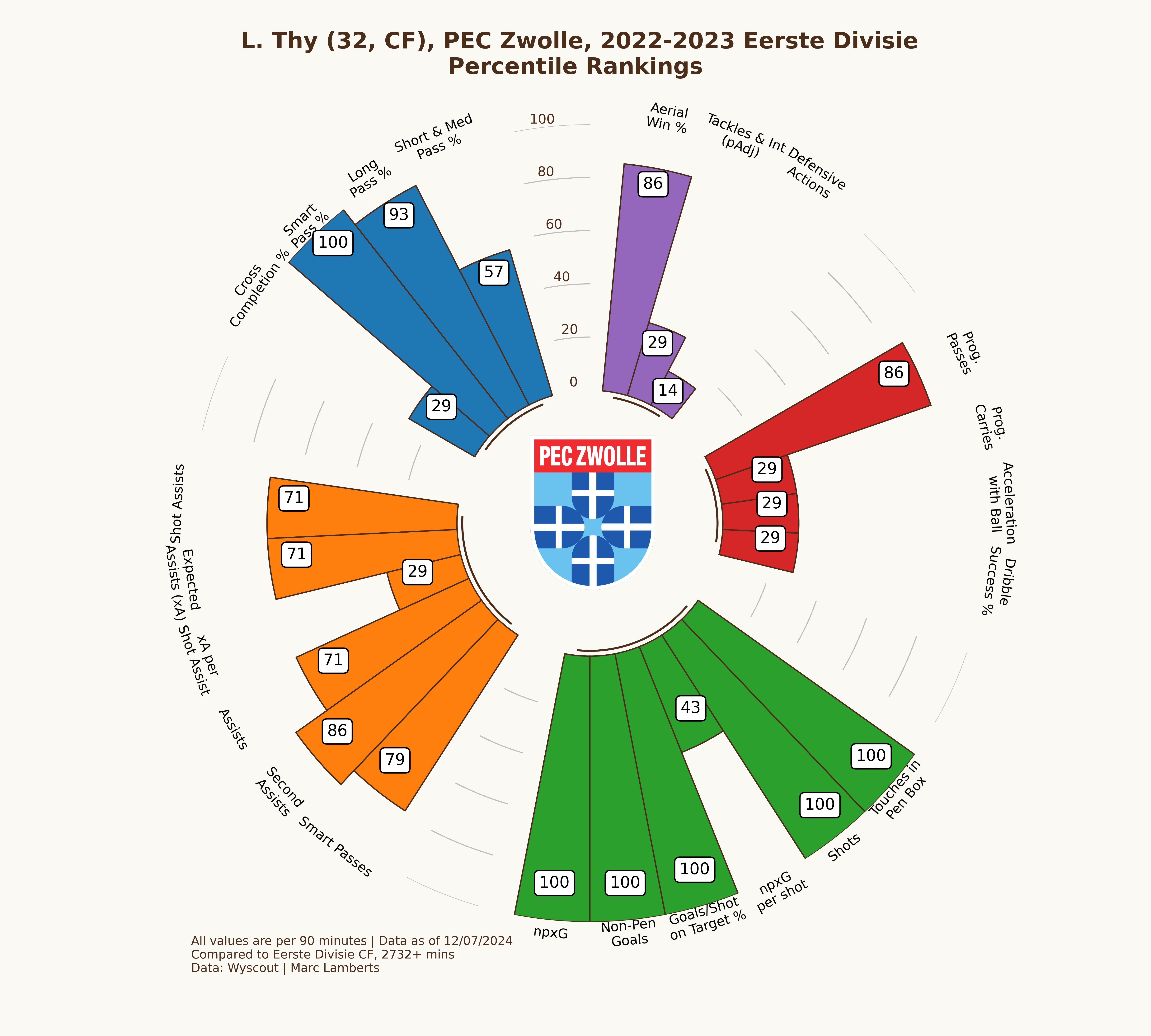
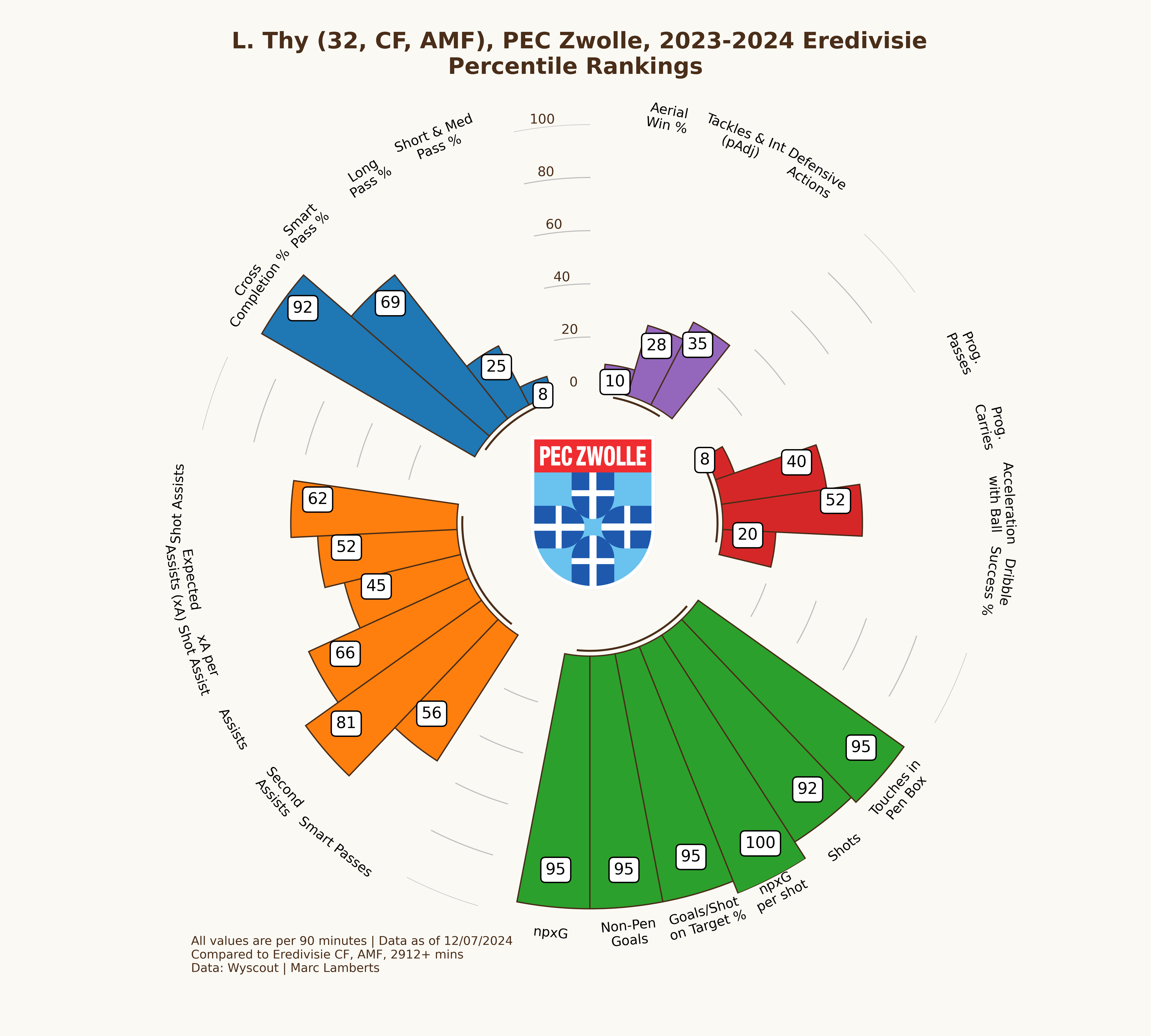
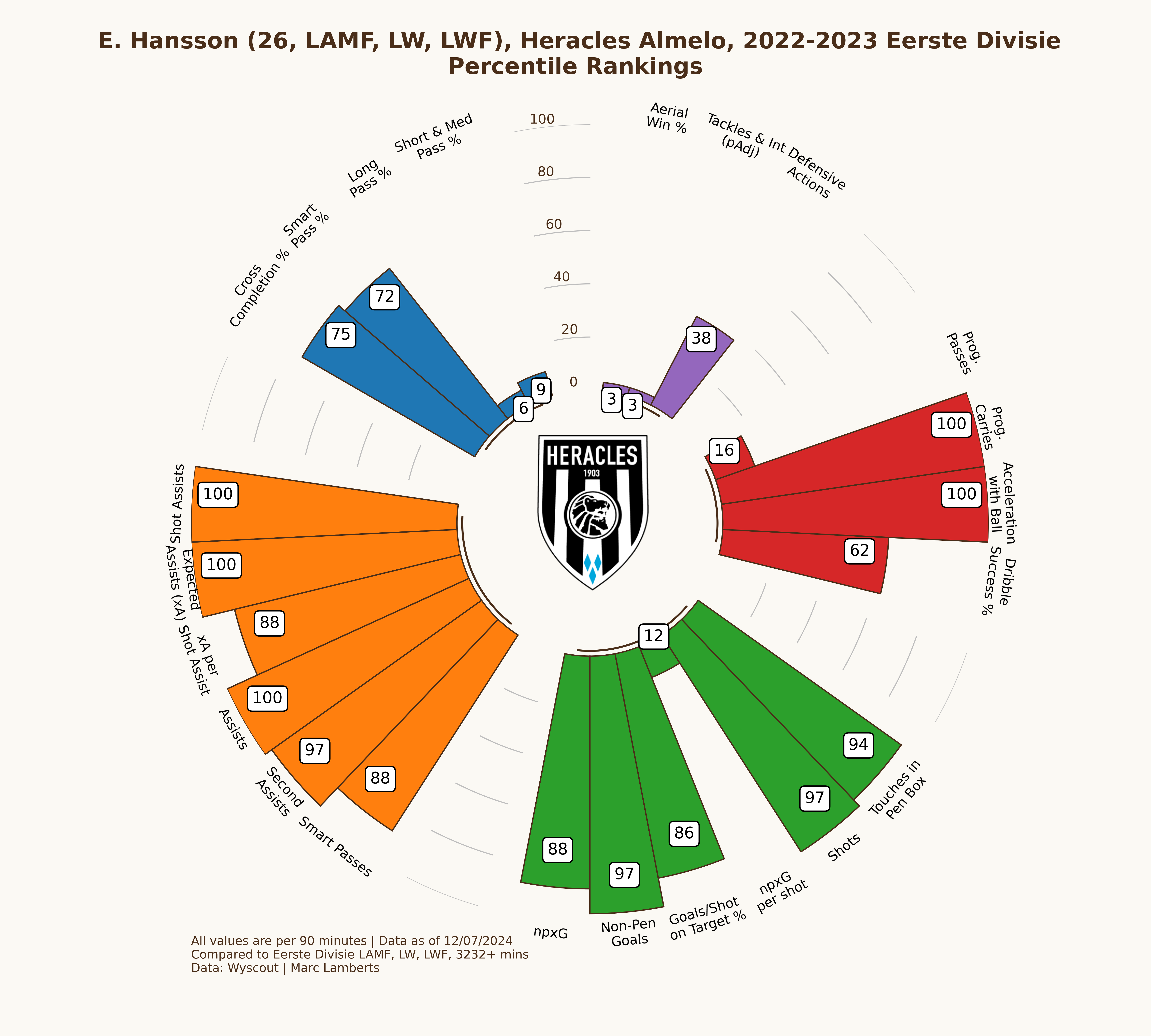
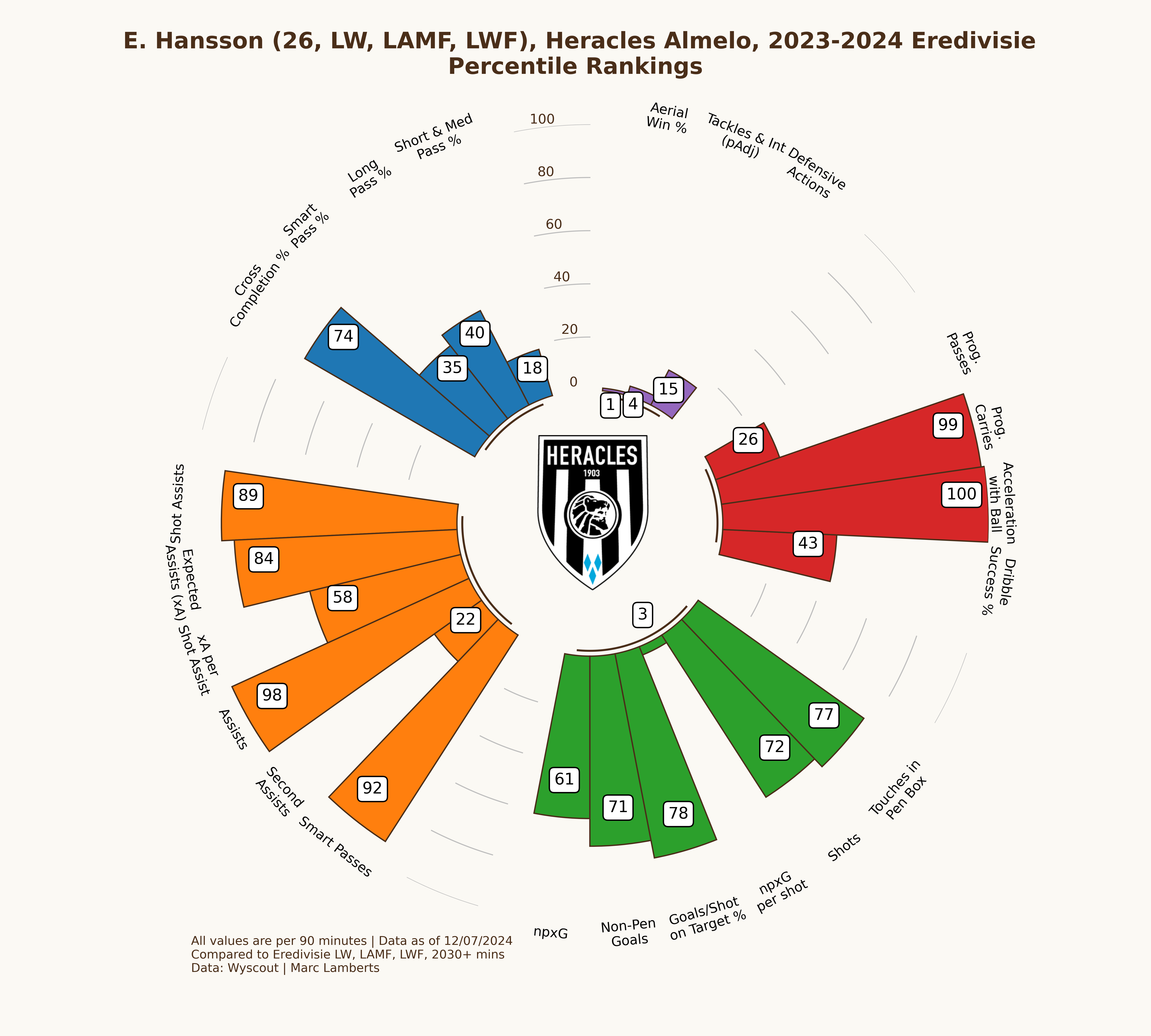
I will pick two different players as a means of experiment. I want to see how the attackers did in the 2022–2023 season in the Eerste Divisie and how they after promotion, they did as attackers in the 2023–2024 Eredivisie. Those players are Lennart Thy from PEC Zwolle and Emil Hansson from Heracles Almelo.
With all that data you need to be able to make a library or a database so it’s ready to use. A vehicle to load in the data, clean it and manipulate it so it’s ready for the research to use. These are what I have used to make sure the research could have been done with the data sources available:
Microsoft Excel: this is where all the data that was stored in a .xlsx or .csv extension was saved in. So when I opened it to look through the data and load it in my programs, I had to use Excel
Python: this is used to load the data, manipulate it and make desirable visualisations. I use it to draw shotmaps, heatmaps and radars of data. It can handle data as well as visualise it — it’s what I use the most for this analysis
R: my xG model is made from a database of 400.000 shots in the Dutch Eredivisie and will convert the event data of shots into shots with xG values. Expected points are also collected from this model, but it’s mostly concentrated on the xG.
What’s most important is that I have the raw data and I want to visualise different possibilities and outcomes connected to shooting data. To make sure I can analyse and visualise it, I need the aforementioned tools that will help me do so.
3. Analysis: Shot locations
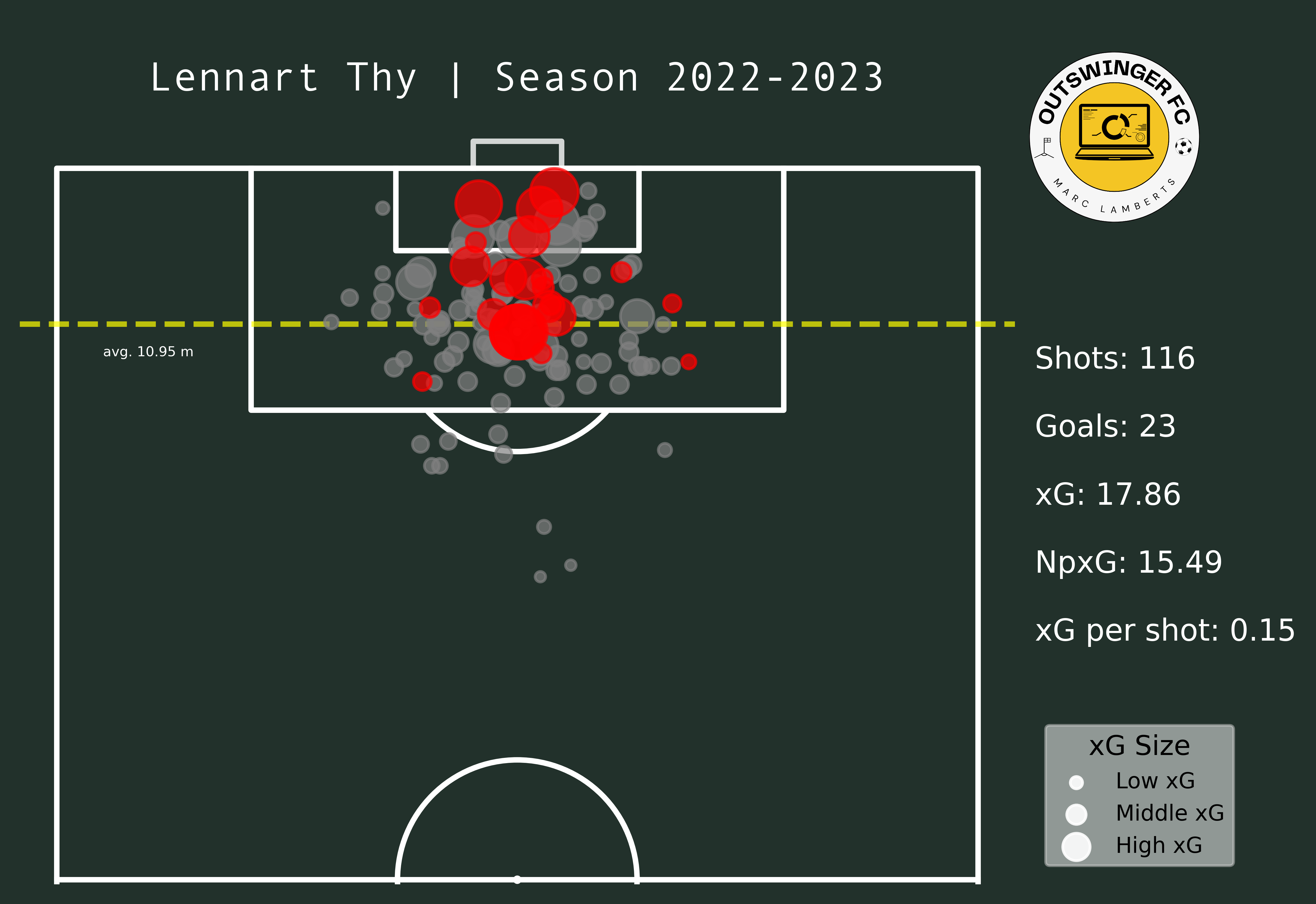
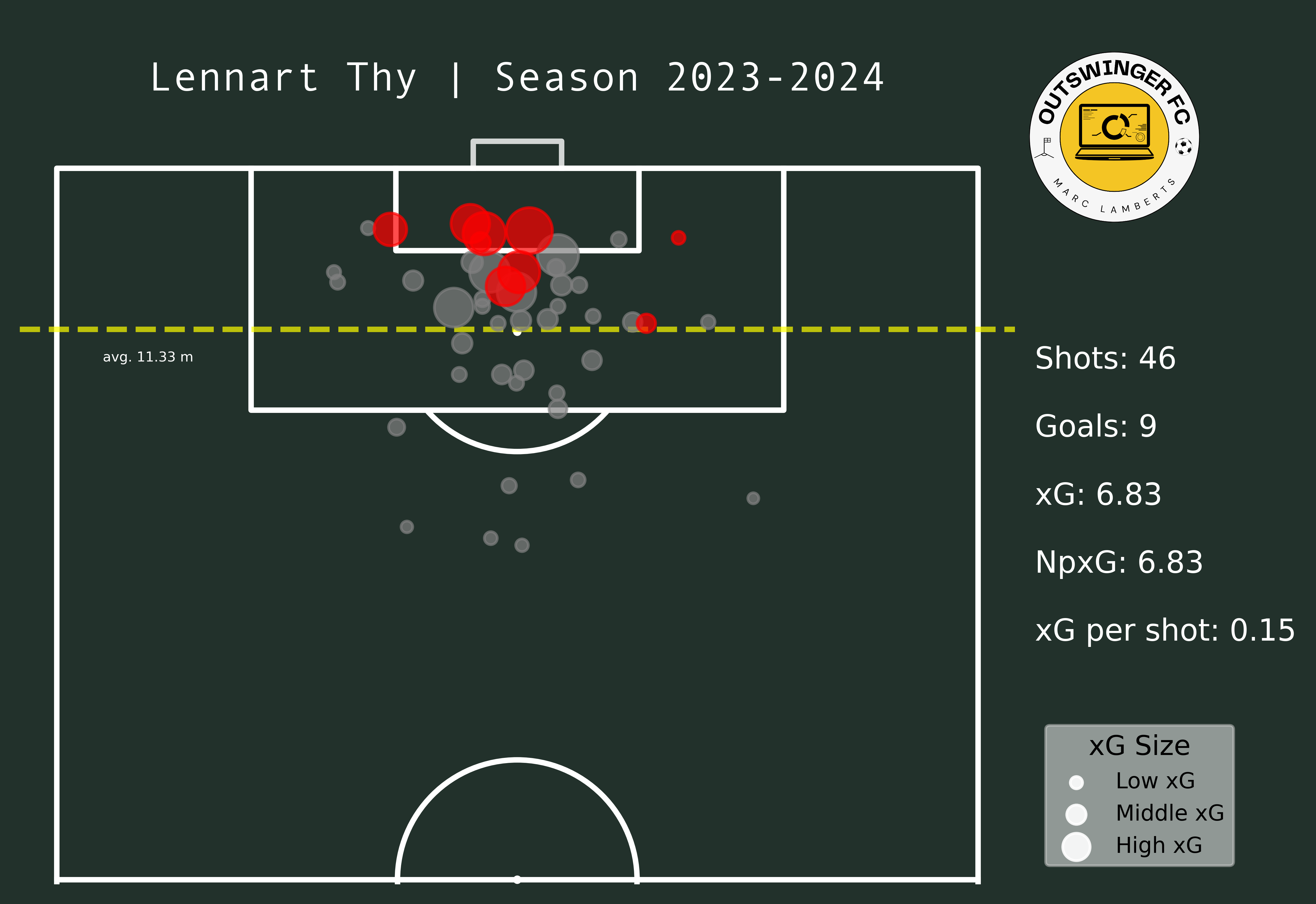
Shot locations will be used to explore where a player conducts his shots from. In the shot maps below you will see the maps of the players in the Eerste Divisie and the Eredivisie next to each other.
In the maps above you clearly see a difference in goals and shots, which can be expected after moving leagues. What I do think is interesting is that the average meters from goal per shot has changed from 10,95 meters to 11,33 meters — which can be an indication of shooting earlier. Having said that, however, the average xG per shot has remained even. This can mean that Thy hasn’t had that much difference in style or shooting between those different leagues.
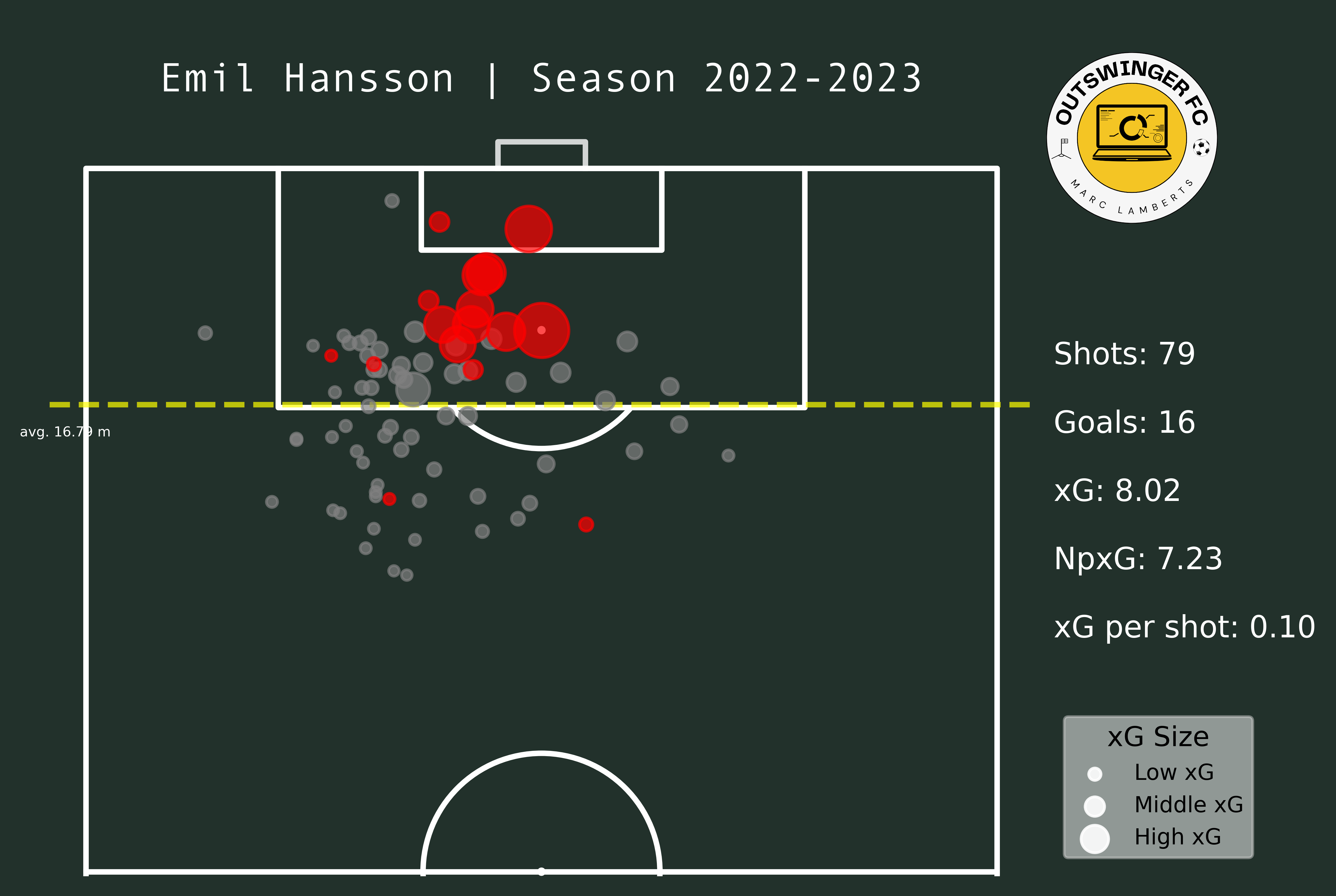
In the maps from Emil Hansson you see a difference altogether. He has significantly fewer shots than in the 22/23 season. But, he is closer to goal and has a better xG per shot than before. This can be an indication that he tries to shoot from locations that give him a better option of scoring.
4. Part of total shooting
We have seen the shot locations in the maps above, but that only tells us a part of the story. We need to see if the effect of promotion also has the effect on the attacker’s importance on the total. You would say that in a higher league, you are resorted to more defending than before and that the role of said attacker is even greater. Can we see this?
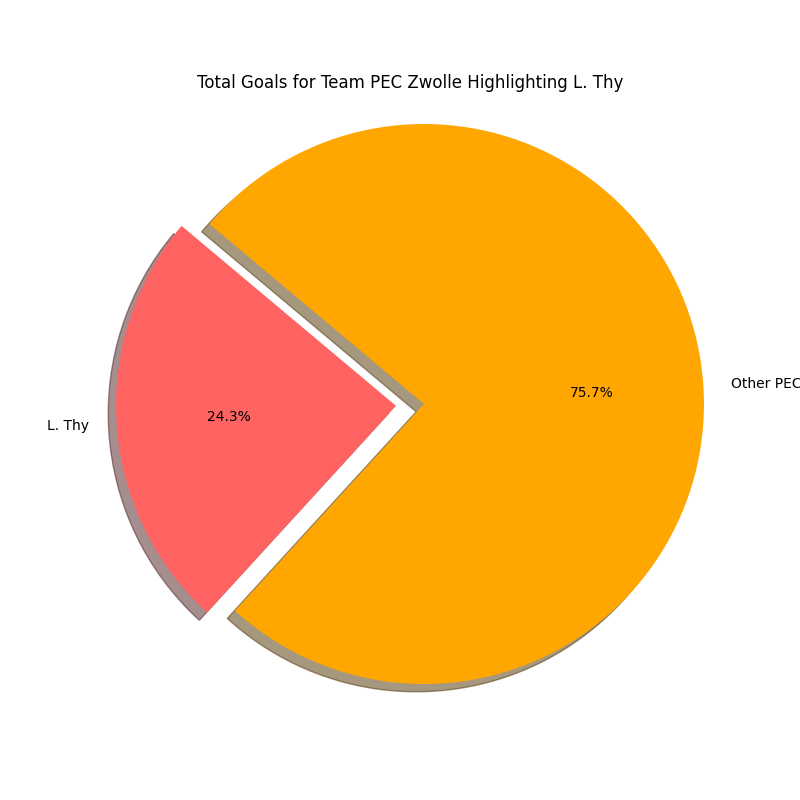
In the pie charts above we can how big the share is of Lennart Thy in the total goals scored for PEC Zwolle in the 2022–2023 Eerste Divisie and the 2023–2024 Eredivisie season. We expected that the share would be higher and it, albeit significantly smaller than we thought before. Thy has gone from 23,2% of goals scored to 24,3% goals scored in the next season, which is a growth of +1,1%.
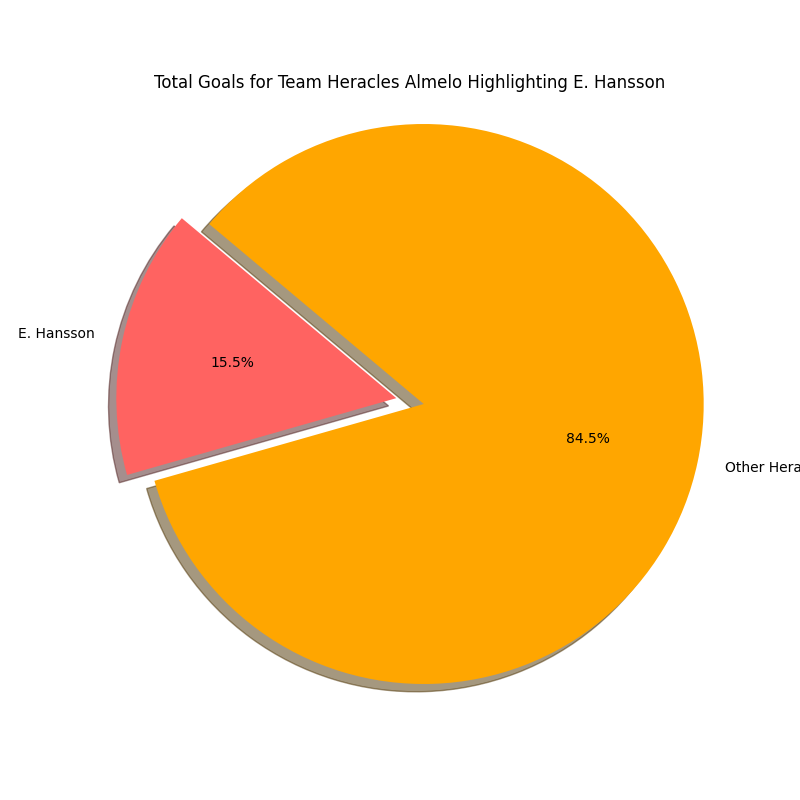
In the pie charts above we can how big the share is of Emil Hansson in the total goals scored for Heracles Almelo in the 2022–2023 Eerste Divisie and the 2023–2024 Eredivisie season. We expected that the share would be higher and it is. Hansson has gone from 15,5% of goals scored to 17,2% of goals scored in the next season, which is a growth of +1,7%.
When the teams are in the higher leagues they resort more to the defensive side of play and the emphasis on scoring goals is trusted with fewer players than in the season where they achieved promotion.
5. Percentile rank radars
In the percentile radars above you can see two radars that look quite identical in some regards and that give me the idea that the player does very well in both leagues. However, there are some little differences: in the shooting metrics Thy really does well, but has become less impactful in aerial wins % and progressive passes. We can make the conclusion that the focus on shooting has become more important and playmaking less important.
While Hansson has become more important for the team to lean on, his quality and being in the top percentiles, something has significantly changed with promotion to the Eredivisie. Especially in the shooting metrics Hansson has gone from the high 80s and 90s to the high 60s and 70s. The differences in leagues and their quality has had an effect on the performances of Hansson.
6. Striking score — CF
From percentile ranks we move on to z-scores. One of the key benefits of z-scores is that they allow for the standardization of data by transforming it into a common scale. This is particularly useful when dealing with variables that have different units of measurement or varying distributions.
By calculating the z-score of a data point, we can determine how many standard deviations it is away from the mean of the distribution. This standardized value provides a meaningful measure of how extreme or unusual a particular data point is within the context of the dataset.
Z-scores are also helpful in identifying outliers. Data points with z-scores that fall beyond a certain threshold, typically considered as 2 or 3 standard deviations from the mean, can be flagged as potential outliers. This allows analysts to identify and investigate observations that deviate significantly from the rest of the data, which may be due to measurement errors, data entry mistakes, or other factors.
With Z-Scores, we calculate the score 50, differently from the 50th percentile. While percentiles look at the middle value or median, Z-scores look at the average or mean of the dataset.
By giving weights to z-scores we can calculate a role for attackers and in doing we can see how well they are within a league. This makes for an interesting concept to see if the fit changes with a promotion to a higher league.
In this example, I will only focus on the striker position. For Lennart Thy, we can conclude that he has a goalscoring striker score of 88,14 out of 100 for the Eerste Divisie 2022–2023. A season later in the Eredivisie his score is 85,25. It seems that he fits better as the goalscoring striker in that specific Eerste Divisie season than he did for the Eredivisie season. This is a logical conclusion as it’s harder to perform in the higher league within that specific role than it is in a tier below.
7. Final thoughts
What I wanted to achieve with this little research was to look into the effect and importance of a promotion. Roles change, dependences change and also the impact of players change. In this first part of the research we have seen how players will grow in their percentage of goals, but might have a more restricted role in relation to what they had previously. Attacking players need to be there primarily for scoring goals in a division higher because you can’t afford to not take those chances.
The next article will focus less on how stable a player engages in attacking actions but will pose to create a metric that measures what promotion does to a player’s performances. To make an adjusted score to see how well a player is doing when coming from a tier lower.
“Data does tell facts and therefore always is the truth” — how often I’ve heard this, I can’t even count the number. I think this is such a weird way of looking at data, as data is a construct so if anything, it’s always subjective and prone to bias. One of the cases is how you deal with match-level generic data provided by data providers.
Within Wyscout you have a scala of different leagues that are provided with data. And, in general, I think that’s really great to have such coverage over different leagues all over the world. Now, what I have noticed is that these leagues are often categorised in terms of tiers. For example, you have Serie C in Italy (3rd tier), National League North/South in England (5th tier) and Regionalliga in Germany (4th tier) — which are all covered in the data within the same dataset, despite having different leagues. That’s why I’m going to look a little deeper into the data for the Regionalliga.
The idea is to see how shots are conducted in the different subdivisions of this tier. Not every league has the same style of play, which will also be reflected in the data — without making the distinction, the data is effectively skewed.
The leagues
There are 5 different leagues within the 4th tier we call the Regionalliga:
Regionalliga Nord
Regionalliga Nordost
Regionalliga West
Regionalliga Südwest
Regionalliga Bayern
The first thing we will need to clarify is that we need access to all data to make something work and that our conclusion from this article needs to concise as possible. So, here we encounter the first problem: only 4/5 leagues are completely accessible in terms of data. Regionalliga Nordost has two teams available in terms of data, so we have to exclude them from what we are trying to achieve here.
That still leaves us with approximately 2000 players across four leagues that will make up the style of each division.
Method
In the method, we look at how I will gain results. The aim is to look at how the different leagues have similarities/differences. I want to look at two different things:
The volume of shots per league by looking at the total shots.
Expected goals per 90 and looking at the differences between the leagues.
I will use the Wyscout data and analyse these metrics, after which I will try to visualise it.
Shots
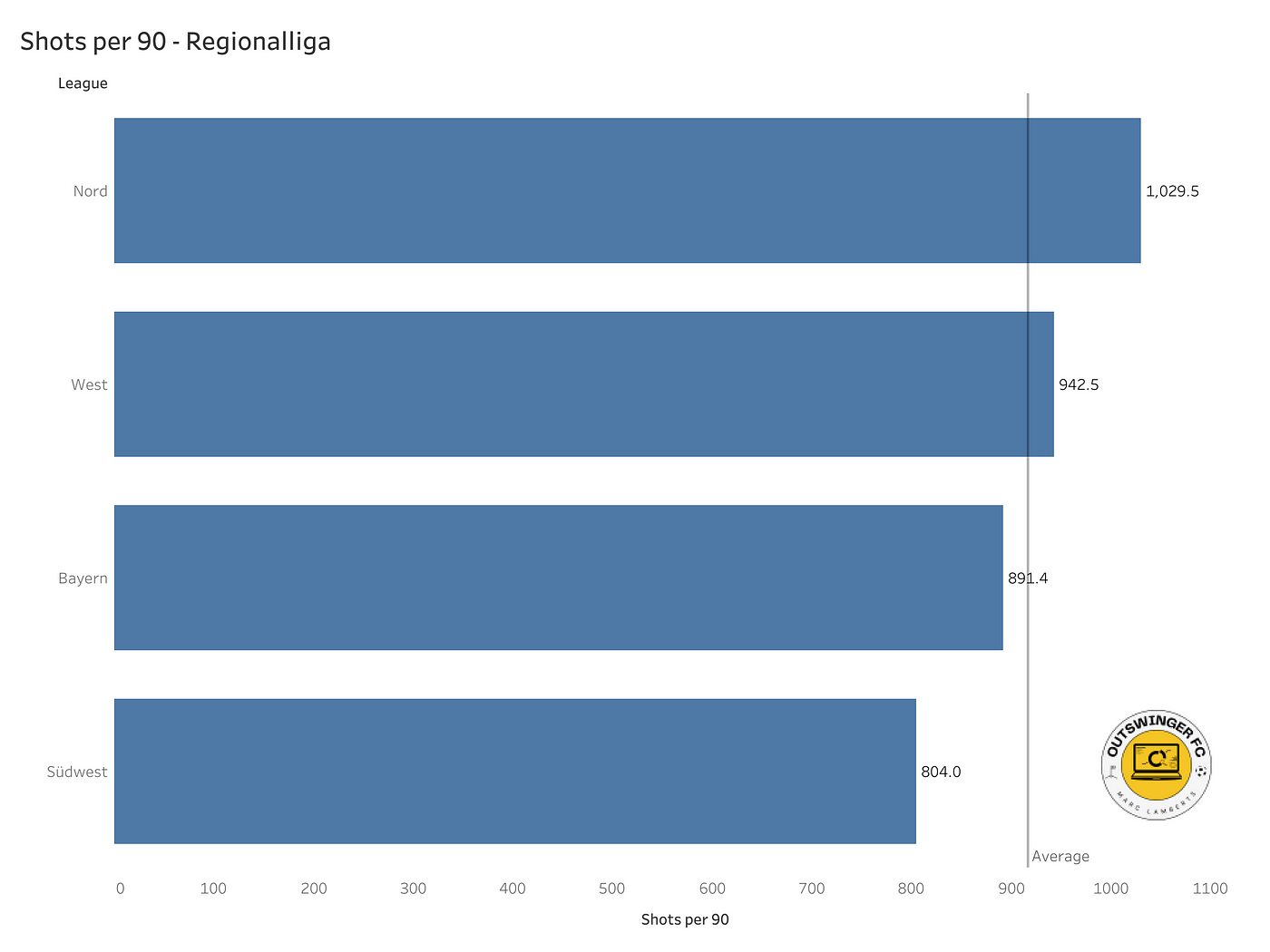
In the bar graph above you can see the four Regionalligas we are looking at and we can see the shots per 90 per league.
As we can see the volume of shots per 90 is the highest in the Regionalliga Nord and the lowest in the Regionalliga Südwest. West and Nord are above the average while Bayern and Südwest are below the average.
It’s too early to have a conclusion ready but it looks like the emphasis on more shots is prevalent in Nord and West, which could indicate they look to shoot more.
Expected goals
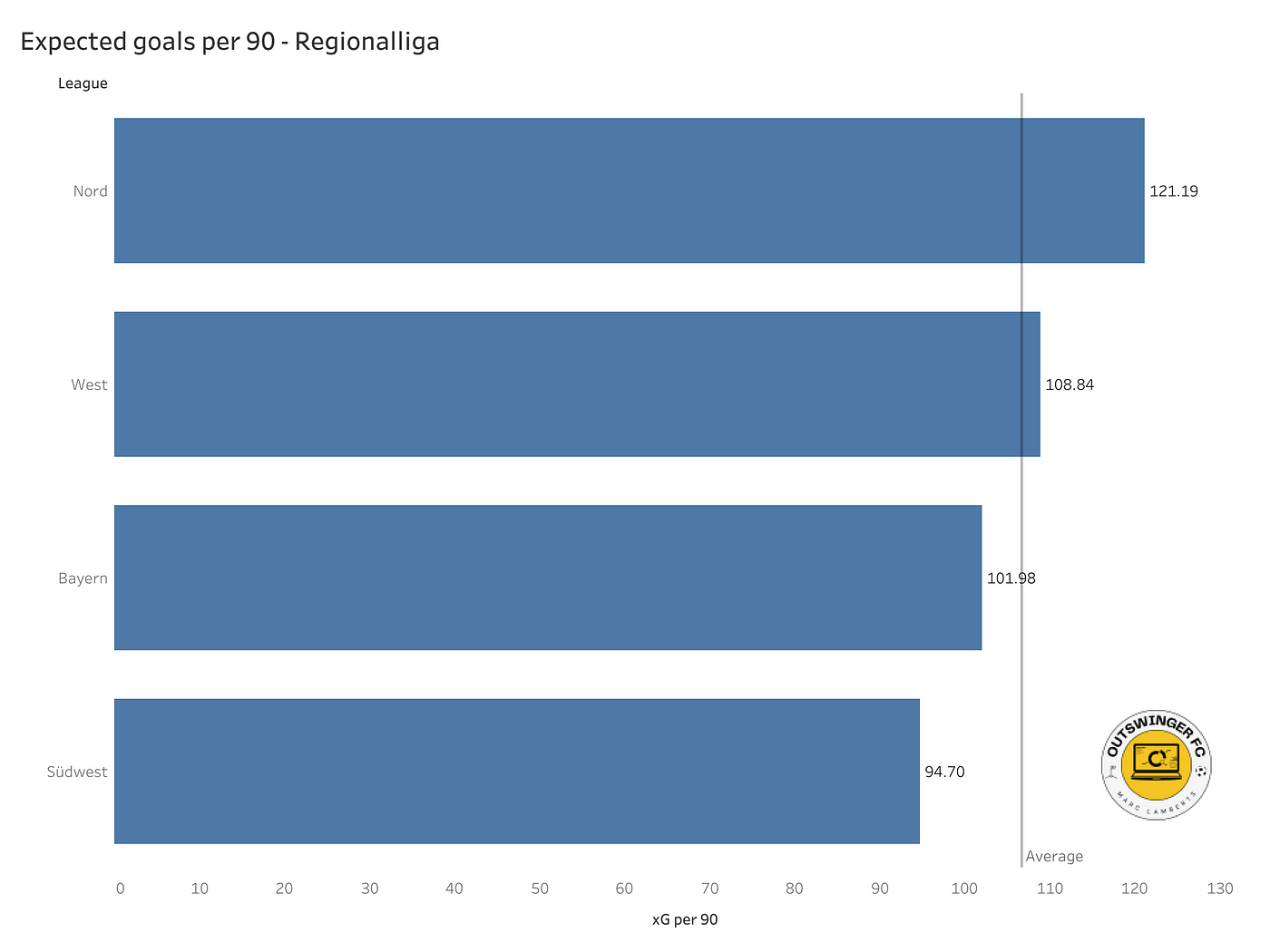
In the bar graph above you can see the four Regionalligas we are looking at and we can see the xG per 90 per league.
It gives us the same idea, but Regionalliga Nord is just a different league in comparison with West and Bayern. Südwest is the other outlier and we can draw a simple conclusion: there are fewer shots and as a consequence, there is also a lower xG per 90 in that specific league.
Conclusion
I think it’s very hard to draw definitive conclusions just from a few data points, but it has to trigger your mind that not all regional leagues are the same.
But, if we are looking to use these metrics for forwards, there are two quite interesting conclusions to draw:
If you have a high number of shots and xG in Regionalliga Südwest, that means more than in the Regionalliga Nord.
If you have low shots in Regionalliga Südwest it’s less damning than having it in Regionalliga Nord
We can of course go deeper into this, but it’s important to link the individual clubs to the league they are playing. If we want to gauge whether a match can be made to the 3. Liga for example, it’s important to look at the league the player is in. Not all 4th tiers are the same.